This material is based on Patrick Green’s presentation at the 1/25/22 LArSoft Coordination Meeting, LArTPC simulation and data-processing with Theta.
Overview
Thanks to the work of Patrick Green (University of Manchester), Misha Salim (Argonne Leadership Computing Facility) and Corey Adams (Argonne Leadership Computing Facility) there has been a demonstration of efficient running of unmodified LArSoft at large scale on the Theta supercomputer (~260,000+ cores) in late 2021, using an end-to-end production workflow for an SBND test sample. This is the first full scale production with LArSoft on an HPC.
Theta is useful for large, computationally demanding samples, such as simulating and reconstructing a very high-statistics cosmic sample. Although challenges remain in handling output files on Theta, and sample transfer from ANL to FNAL is a bottleneck, producing this type of sample on the grid would be extremely time consuming. Documentation for running SBND production on Theta is available at: https://sbnsoftware.github.io/sbndcode_wiki/SBND_at_Theta
Background on Theta and LArSoft
 The Theta supercomputer at the Argonne Leadership Computing Facility (ALCF) has 4392 nodes, with 64 cores per node, so can run 281,088 jobs simultaneously. LArTPC simulation and data processing is suited to run on an architecture like Theta since it is event based with large scale processing that is easily made parallel.
The Theta supercomputer at the Argonne Leadership Computing Facility (ALCF) has 4392 nodes, with 64 cores per node, so can run 281,088 jobs simultaneously. LArTPC simulation and data processing is suited to run on an architecture like Theta since it is event based with large scale processing that is easily made parallel.
The SBND simulation and reconstruction effort on SBND used LArSoft standard releases with the binaries copied to Theta via pullProducts. The code was run using Singularity containers with some minor modifications required to avoid FNAL system specific code – e.g. ifdh, database access.
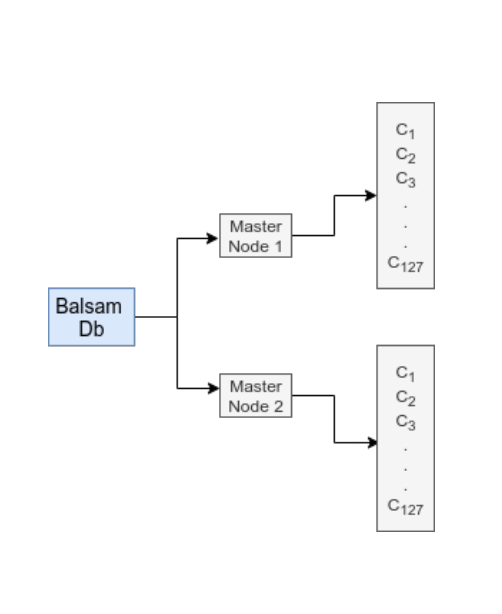
The sample was split into single, or a small number, of event jobs. A separate core processed each job with the output merged into files of N events. Balsam managed large scale production by automating the splitting, running and merging of events.
Globus transferred data between Theta and Fermilab at speeds up to ~1.2 GB/s. This may be able to be increased and there is potential to automate file transfer using Balsam.
To transfer files to tape, POMs metadata extractor scripts were modified to work with Theta generated files. From there, the standard FTS plugin / dropbox system automated extraction of metadata, declaration to SAM and transfer to tape-backed storage. Theta produced samples could then be treated identically to standard production samples by analyzers.
Scaling the workflow
Once a functioning workflow was obtained, the task was to get it running efficiently at a large scale. A typical large scale application in LArSoft would internally use many cores/nodes with a separate instance of LArSoft running on each individual core. Initially, this led to major bottlenecks / overhead costs, which were evident in a drop of CPU efficiency from ~95% at ~250 cores, to ~30% at ~8000 cores.
 The two main bottlenecks resulted from the need to run separate instances of LArSoft on each core:
The two main bottlenecks resulted from the need to run separate instances of LArSoft on each core:
- Balsam MPI: the master process struggled to keep > 50% cores occupied at 128 nodes. This was resolved at small-mid scale via substantial optimisation of Balsam. Larger scales were achieved by splitting into multiple master processes.
- LArSoft I/O: – LArSoft binaries are read and outputs are written per process, easily overloading central Lustre file-system – mitigated by making use of local SSDs available to each node, and minimizing copying to/from central file-system
After these changes, scaling was again tested with reproducible reconstruction of simulated Corsika cosmics in SBND (reco1 & reco2). In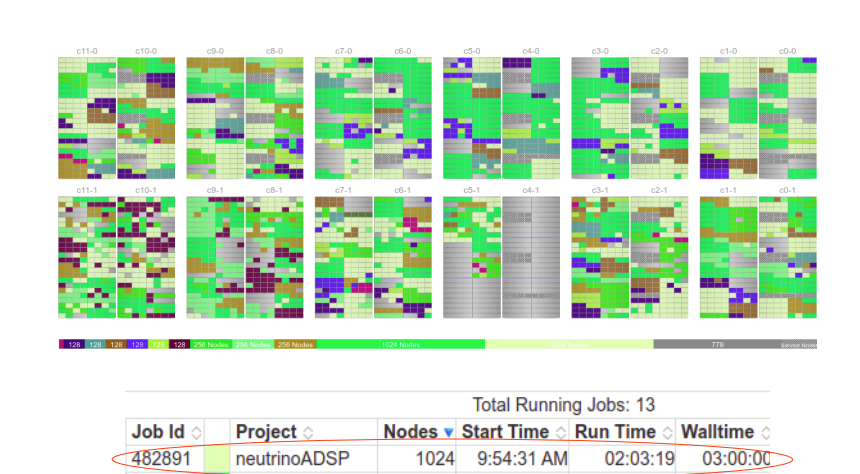 this test, efficient throughput was achieved at large scale:
this test, efficient throughput was achieved at large scale:
- ~95% efficient at 4096 nodes
- 260,000 simultaneous jobs
- 6.5M cosmics reconstructed in 1 hour
A similar job on the grid would take days.
While it is possible to run LArSoft without modification, as was done in this demonstration, enabling the use of AVX-512 vector processing would improve performance.
Remaining issues include:
- Running separate instances of LArSoft on each core is inefficient and has a large initial cost in initialization of classes, etc. that can be a significant fraction of total run time when generating smaller numbers of events. This adds to stress on the file-system with a large number of instances all trying to write in an uncoordinated way. A more optimal scenario would be one instance of LArSoft per node, that internally can run one event per core. Using a fully thread-safe workflow and the built-in multi-threading capabilities of art would address this problem.
- Size of output files is challenging. The I/O requirement is overwhelming, e.g. cosmic reconstruction jobs writing ~350TB per hour @ 4096 nodes. During the 2021 testing, the team was unable to save files during benchmarking, and had to immediately delete them due to space limitations.
- File transfer to FNAL and saving to tape is a primary bottleneck for production. This would need to be sped up substantially to keep up with the pace of production on Theta. An alternative is to store files at ALCF (on Eagle) and create a system for analyzers to access via globus.
There is a wiki page on GitHub that documents how to run production on Theta at ALCF. Although written for SBND, the documentation was designed to be easily adaptable for any experiment code running LArSoft. It is available at:
https://sbnsoftware.github.io/sbndcode_wiki/SBND_at_Theta
For further details, please see Patrick Green’s presentation at the 1/25/22 LArSoft Coordination Meeting.