This material is based on Sophie Berkman’s presentation Reconstruction for LArTPC Neutrino Detectors Using Parallel Architectures at the 20th International Workshop on Advanced Computing and Analysis Techniques in Physics Research (ACAT 2021), and the paper Optimizing the Hit Finding Algorithm for Liquid Argon TPC Neutrino Detectors Using Parallel Architectures [1].
Overview
LArSoft algorithms can be modified and optimized to take full advantage of the acceleration and multi-threading capabilities of a particular HPC resource to run with maximum efficiency. Here we present an example of optimizing code to run efficiently on HPC platforms using a native build of LArSoft.
 Liquid argon time projection chamber (LArTPC) neutrino experiments are expected to grow in the next decade to have more wires than currently operating experiments, and processing the data from bigger detectors efficiently will be a challenge. The processing is already a limiting process, even in smaller current generation LArTPCs. The reconstruction time in a state-of-the-art experiment such as MicroBooNE is on the order of minutes per event. The next generation of experiments such as ICARUS and DUNE will produce even more data with 5 and 100 times more wires respectively. Large increases in reconstruction speed are needed to be able to efficiently process the data from these experiments. Modernization of LArTPC reconstruction code, including parallelization both at data- and instruction-level, will help to mitigate this challenge.
Liquid argon time projection chamber (LArTPC) neutrino experiments are expected to grow in the next decade to have more wires than currently operating experiments, and processing the data from bigger detectors efficiently will be a challenge. The processing is already a limiting process, even in smaller current generation LArTPCs. The reconstruction time in a state-of-the-art experiment such as MicroBooNE is on the order of minutes per event. The next generation of experiments such as ICARUS and DUNE will produce even more data with 5 and 100 times more wires respectively. Large increases in reconstruction speed are needed to be able to efficiently process the data from these experiments. Modernization of LArTPC reconstruction code, including parallelization both at data- and instruction-level, will help to mitigate this challenge.
As described in a 2022 paper [1], the hit finding algorithm used by LArTPC experiments has been optimized for execution on parallel CPU architectures by multi-threading the algorithm at multiple levels and replacing code with a vectorized implementation.
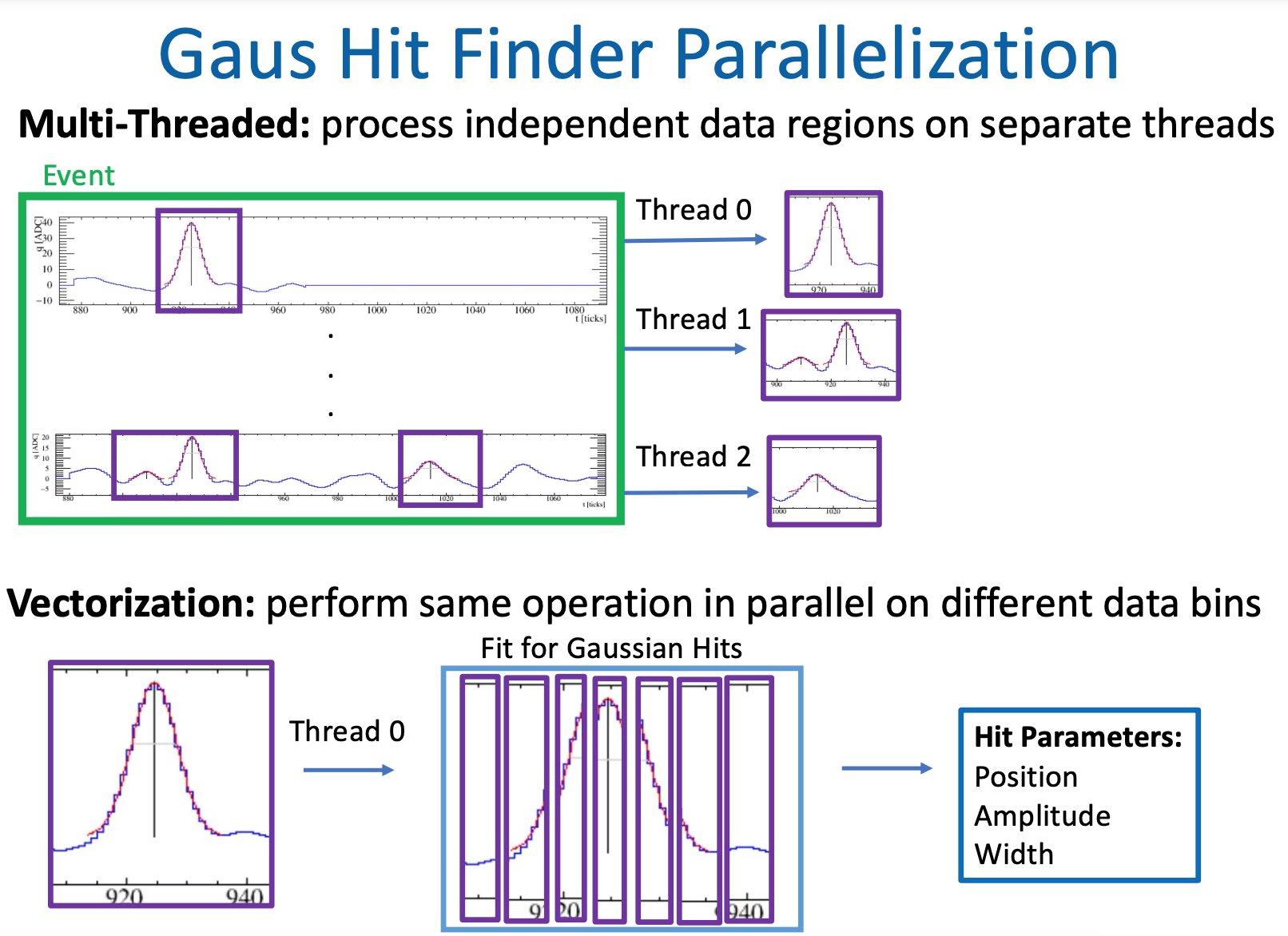 The hit finding algorithm is well suited to demonstrate the potential speedups that may be gained by parallelization of LArTPC reconstruction because each of the wires and ROIs can be independently processed. While this is a simple algorithm, it takes a significant fraction of the reconstruction time, ranging from a few percent to several tens of percent of the total, depending on the experiment. Any increases in speed will have a demonstrable impact on the experiment processing times.
The hit finding algorithm is well suited to demonstrate the potential speedups that may be gained by parallelization of LArTPC reconstruction because each of the wires and ROIs can be independently processed. While this is a simple algorithm, it takes a significant fraction of the reconstruction time, ranging from a few percent to several tens of percent of the total, depending on the experiment. Any increases in speed will have a demonstrable impact on the experiment processing times.
In a standalone environment, vectorization made the hit finding algorithm twice as fast. Multi-threading at the event and sub-event levels led to speedups of up to 100 times on an Intel Xeon Phi Processor 7230 (Knights Landing, KNL) and 30 times on an Intel Xeon Gold 6148 (Skylake, SKL). KNL results were obtained on the Argonne Leadership Computing Facility (ALCF) high performance computer Theta. Tests were performed with a sample of 1000 events of MicroBooNE neutrino simulation overlaid with cosmic muon data, including the real noise and detector response. After integrating this version of the hit finding algorithm into LArSoft, the new algorithm was found to be 7-12 times faster, depending on the experiment, than the original before parallelization, while producing identical physics results. Vectorization and multi-threading performance within LArSoft is found to be similar to that of the standalone. This hit finder is now used by the ICARUS and ProtoDUNE experiments.
This work can be expanded to apply similar techniques to the optimization of other algorithms, introducing additional algorithm parallelism in LArTPC reconstruction and making these algorithms available to experiments through processing at HPCs.
References
[1] S. Berkman, et al., “Optimizing the Hit Finding Algorithm for Liquid Argon TPC Neutrino Detectors Using Parallel Architectures”, JINSST 17 (2022) 01, P01026. e-Print: 2202.00812 [physics.ins-det])