This material is based on Michael Wang’s presentation Using GPUaaS in LArSoft with the NuSONIC inference client interface given at the LArSoft Coordination meeting in August of 2021 and the paper by Michael Wang et al. GPU-Accelerated Machine Learning Inference as a Service for Computing in Neutrino Experiments.
The data in LArTPC based experiments are suited to a deep learning approach. However, deep learning inference tasks are inefficient on CPU-centric grid worker nodes and results in a dramatic increase in the computational workload of LArTPC reconstruction workflows. Accelerator hardware like GPUs are purpose built for deep learning-like applications, but how to use them has been an issue. LArSoft tools provide a practical way to deploy GPUs “as a service” (GPUaaS).
The details on using GPU as a service to accelerate machine learning inference applications are available at the following links:
- Part One: Overview and introduction to the NuSonic Triton client library
- Part Two: Setting up the model on the Triton inference server
- Part Three: Testing the Triton client and model configuration with an inference server
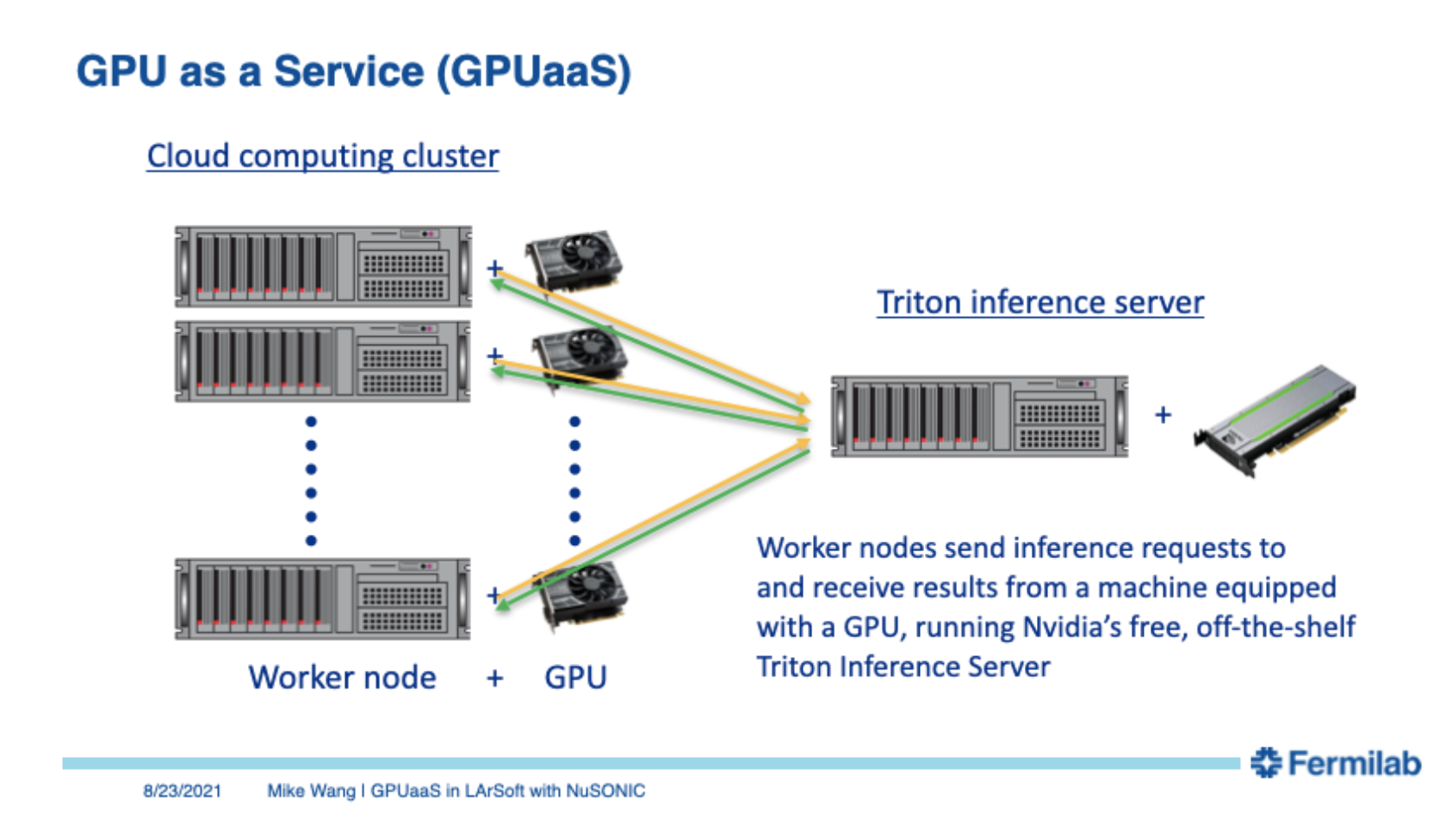
From: https://indico.fnal.gov/event/50528/
In 2021, a proof-of-principle was demonstrated by applying GPUaaS to the EMTrackMichelId module in the ProtoDUNE workflow. This module uses a CNN to classify hits as being shower-like, tracklike, or Michel electron like. Details of the implementation including scaling studies using an inference server deployed on a 4-GPU Kubernetes cluster on the Google cloud platform are described in a paper: GPU-Accelerated Machine Learning Inference as a Service for Computing in Neutrino Experiments
While the proof-of-principle used the Nvidia Triton C++ client library API directly in the relevant LArSoft code for EmTrackMichelId, but since then work has been done on the NuSONIC inference client library, which is a layer sitting on top of the Triton C++ API. It is based on CMSSW’s SONIC (Services for Optimized Network Inference on Coprocessors), essentially a pared down version retaining only components most relevant for LArSoft.
After prerequisites are met, the steps to follow are:
- Creating the client
- Describe or prepare the data for the corresponding model input
- Send the inference request to the server
- Retrieve the inference results from the server
Details are available in a powerpoint presentation titled Using GPUaaS in LArSoft with the NuSONIC inference client interface given at the LArSoft Coordination meeting in August of 2021.