LArSoft Multi-threading workshop March 2023
The LArTPC multi-threading and acceleration workshop in early March was well attended with 43 people registered. It was hybrid with in-person and online options available. There was one day of presentations spread across two morning sessions. The presentations for the first morning were on existing tools and support. The second morning was experiments’ tools and experiences. Slides are available for each presentation by clicking on the title. Most sessions were recorded. The images come from each presentation that is described.
Welcome and Introduction by Adam Lyon. Adam discussed the lab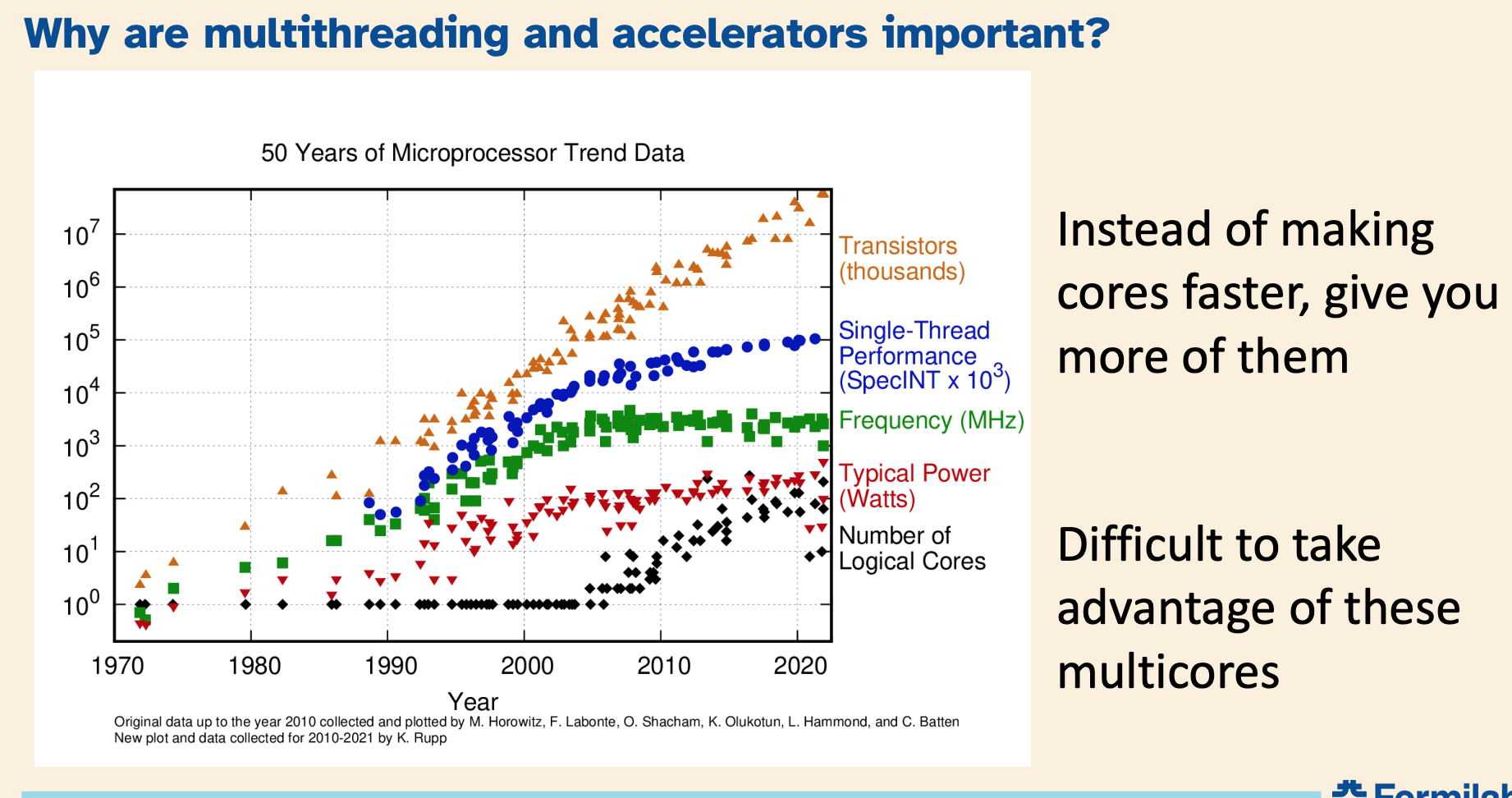 reorganization and the mission of the Data Science, Simulation and Learning division. He talked about why multithreading and accelerators were important. These remarks were not recorded.
reorganization and the mission of the Data Science, Simulation and Learning division. He talked about why multithreading and accelerators were important. These remarks were not recorded.
Introduction to Workshop by Erica Snider gave the reasons for a multi-threading and acceleration workshop. The goals of the workshop are:
- To learn the multi-threading and acceleration capabilities of frameworks and common toolkits used by LArTPC experiments;
- To share experiences across experiments about existing resource utilization and throughput problems that lend themselves to multi-threaded or acceleration solutions;
- To explore how multi-threading and acceleration is being used to address these problems and open avenues to the use HPC resources more broadly;
- To discuss the results of applying these techniques and capabilities
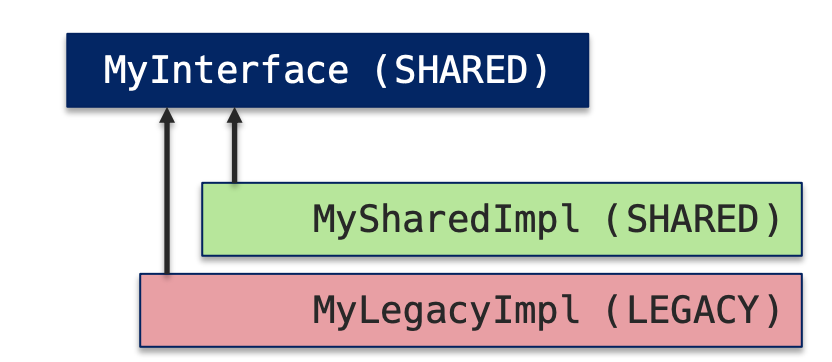 Multithreading support in LArSoft was presented by Kyle Knoepfel who covered background about art and LArSoft services that must have a scope of SHARED in order to run in multi-threaded contexts. SciSoft team efforts have primarily focused on making LArSoft service providers and services thread-safe/efficient. The thread-safety approach used depends on the context.
Multithreading support in LArSoft was presented by Kyle Knoepfel who covered background about art and LArSoft services that must have a scope of SHARED in order to run in multi-threaded contexts. SciSoft team efforts have primarily focused on making LArSoft service providers and services thread-safe/efficient. The thread-safety approach used depends on the context.
Kyle mentioned previous presentations as useful resources on this topic. These include:
- 2017 presentation Introduction to multi-threading
- 2019 Presentation – Multi-threaded art
- 2019 Presentation – Making code thread-safe
- 2019 Presentation (powerpoint download) – Experience learning to make code thread-safe
- 2019 Presentation Introduction to multi-threading and vectorization
Handling External Libraries with Conflicting Thread Pools was presented by Christopher Jones. Multiple thread pools used for heavy computation are problematic. He discussed strategies and conditions that allow multiple thread pools to run efficiently.
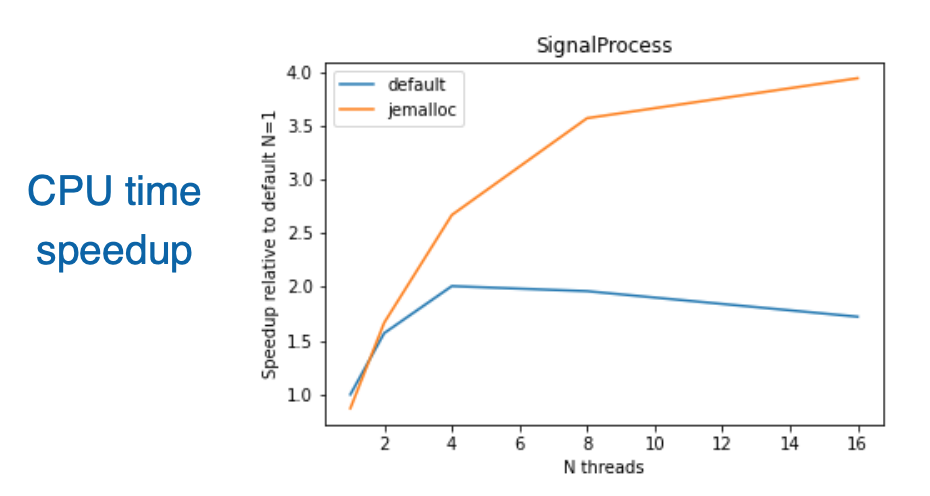 Giuseppe Cerati presented Parallelization in LArSoft reconstruction – SciDAC4 developments. The mission was to accelerate HEP event reconstruction using modern parallel architectures.
Giuseppe Cerati presented Parallelization in LArSoft reconstruction – SciDAC4 developments. The mission was to accelerate HEP event reconstruction using modern parallel architectures.
Soon Yung Jun presented Geant4 Multithreading and Tasking.

Geant4 supports a task-based framework (G4Tasking) suitable for multithreading, concurrent tasking and heterogeneous workflows.
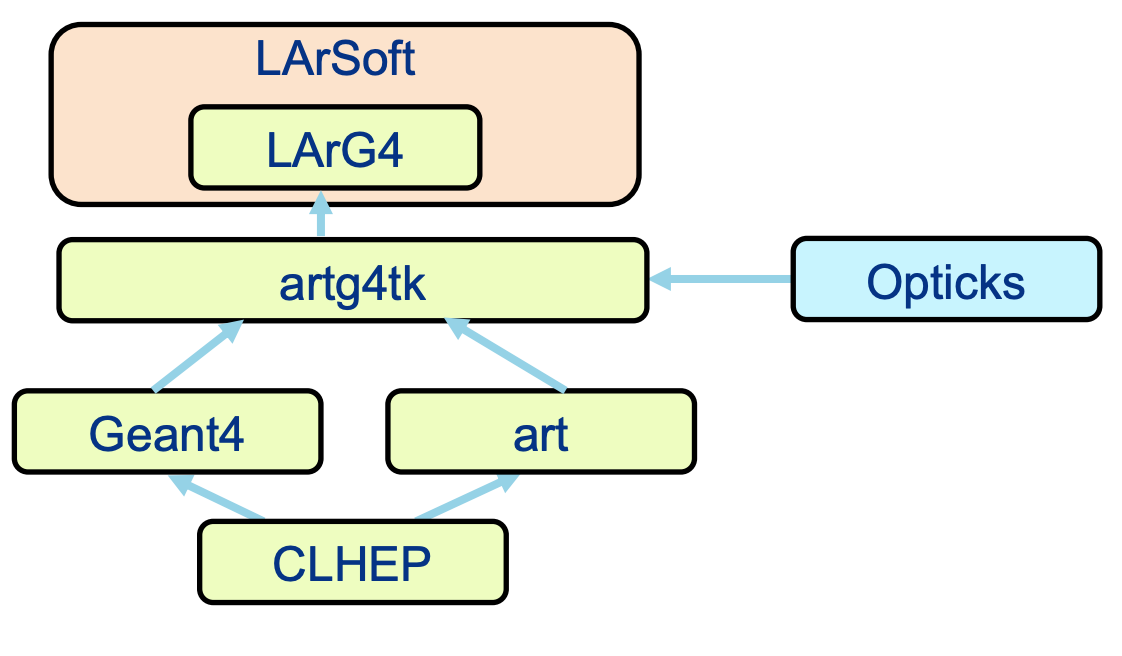 Hans Wenzel presented Geant4/CaTS/Opticks: optical photon propagation on a GPU. Opticks is an open-source project that accelerates optical photon simulation by integrating NVIDIA GPU ray tracing, accessed via NVIDIA OptiX ®. The computational challenge: Simulating optical photon propagation where a single 2GeV electron shower, for instance, results in about 70 million VUV photons. This is an ideal application to be ported to GPU’s.
Hans Wenzel presented Geant4/CaTS/Opticks: optical photon propagation on a GPU. Opticks is an open-source project that accelerates optical photon simulation by integrating NVIDIA GPU ray tracing, accessed via NVIDIA OptiX ®. The computational challenge: Simulating optical photon propagation where a single 2GeV electron shower, for instance, results in about 70 million VUV photons. This is an ideal application to be ported to GPU’s.
 Brett Viren presented Threads of parallelism with the Wire-Cell Toolkit. Wire-Cell Toolkit executes many ST-coded nodes in parallel across a MT’ed data flow graph. Wire-Cell can run stand-alone or as a part of art + LArSoft.
Brett Viren presented Threads of parallelism with the Wire-Cell Toolkit. Wire-Cell Toolkit executes many ST-coded nodes in parallel across a MT’ed data flow graph. Wire-Cell can run stand-alone or as a part of art + LArSoft.
Haiwang Yu presented Multi-Threading and Acceleration in Wire-Cell Toolkit. Wire-Cell Toolkit Multi-Threading and Acceleration is production ready for MT and PyTorch while Kokkos, IDFT and ZIO need more work.
Ryan Cross presented Threading in Pandora Thoughts & First Look. A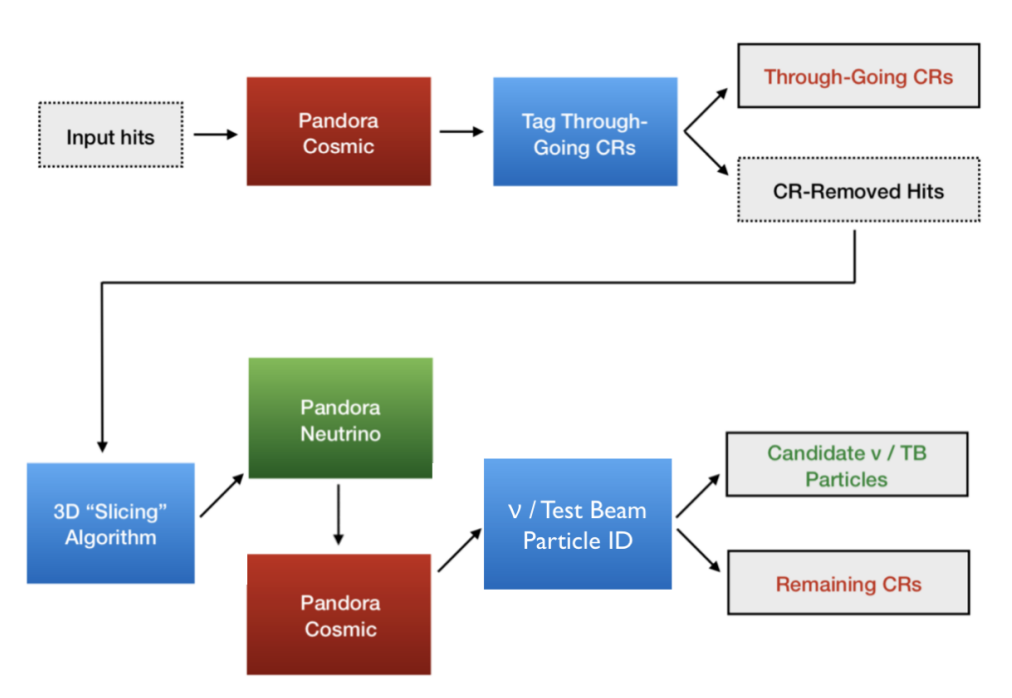 strength of this multi-algorithm approach is the ability to have multiple targeted reconstruction chains. Pandora utilises these different algorithm chains to target different topologies. This may be reconstructing both cosmic ray and test beam interactions in one instance of Pandora, or running different algorithm chains for interactions that have different reconstruction concerns such as atmospheric or supernovae interactions.
strength of this multi-algorithm approach is the ability to have multiple targeted reconstruction chains. Pandora utilises these different algorithm chains to target different topologies. This may be reconstructing both cosmic ray and test beam interactions in one instance of Pandora, or running different algorithm chains for interactions that have different reconstruction concerns such as atmospheric or supernovae interactions.
 Tracy Usher presented ICARUS Multi-threading Production Workflow. ICARUS production data processing at the stage 0 level would benefit from moving to a multi-threaded processing model.
Tracy Usher presented ICARUS Multi-threading Production Workflow. ICARUS production data processing at the stage 0 level would benefit from moving to a multi-threaded processing model.
Tom Junk presented DUNE Data Serialization/Low-Level Processing and Production. Work has been invested in streaming data into jobs in small pieces (smaller than a trigger record), necessary to keep the memory usage down.
 Matt Kramer presented Multi-processing for ND-LAr in larnd-sim and ndlar_flow. Both larnd-sim and ndlar_flow are written in array-oriented Python. They are inherently parallel and ready to take advantage of next-gen GPU (larndsim) and CPU (ndlar_flow) facilities.
Matt Kramer presented Multi-processing for ND-LAr in larnd-sim and ndlar_flow. Both larnd-sim and ndlar_flow are written in array-oriented Python. They are inherently parallel and ready to take advantage of next-gen GPU (larndsim) and CPU (ndlar_flow) facilities.
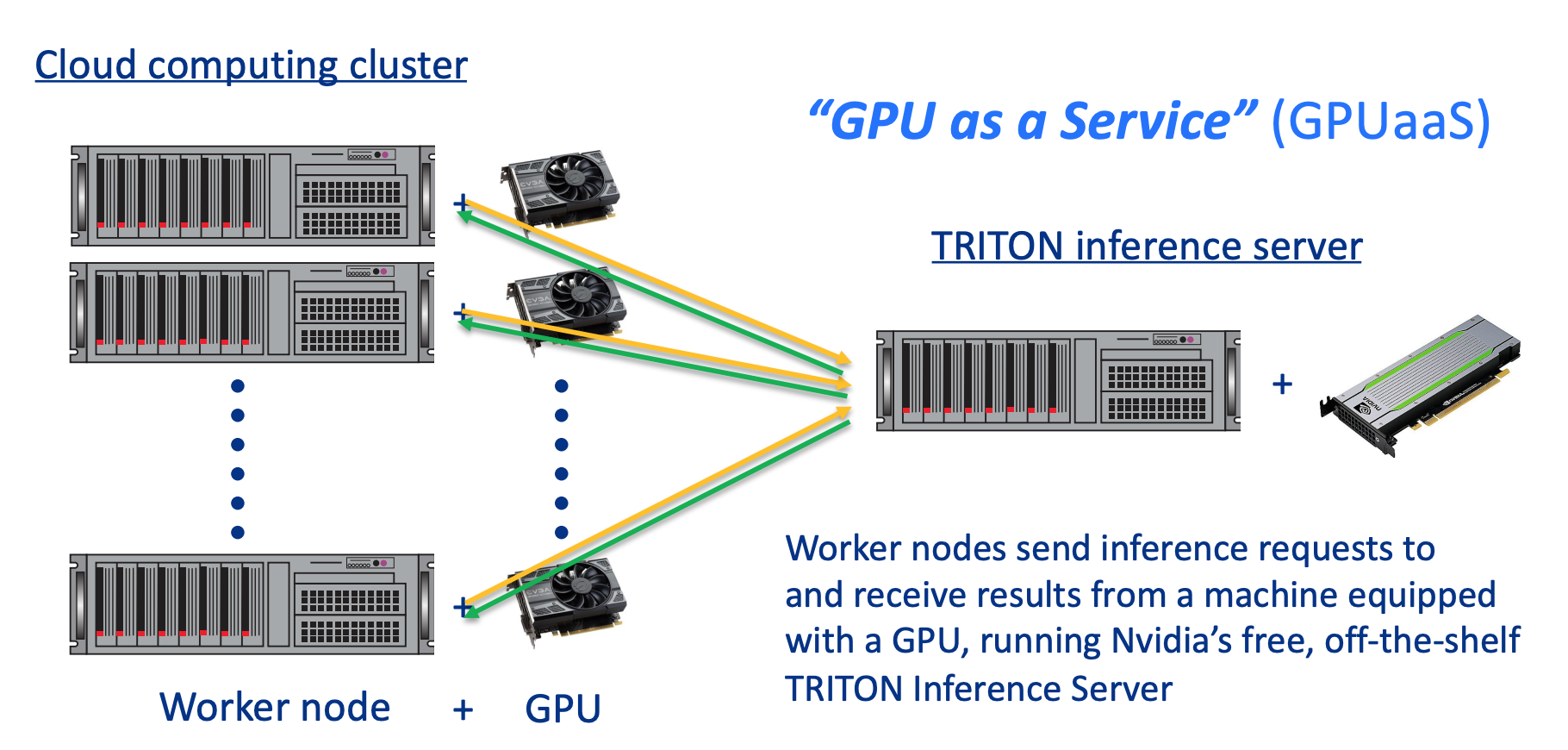
Michael Wang presented GPU as a Service (GPUaaS) for accelerating DL inference applications in LArSoft. Deep learning methods are very well suited to the image-like data in LArTPC based neutrino experiments. GPUaaS is not limited to GPUs, the underlying accelerator or co-processor can be based on other types of hardware like FPGAs, TPUs, GraphCore IPUs, etc. Two detailed sets of studies have been performed and published that characterize the performance of this DL inference acceleration service in LArSoft using ProtoDUNE data.
Slides for the various sessions can be found at: https://indico.fnal.gov/event/57914/ The audience was engaged with robust discussion. Could see that several experiments were adapting plans based on what they were learning.
Recordings can be found at the Indico site for the workshop either under the link for video or in the timetable for each session.