Workshop Overview
The annual LARSoft workshop was held on June 24 and 25 at Fermilab. There were three sessions:
- Session 1: LArSoft tutorial.
- Provide the basic knowledge and tools for navigating, using, writing and contributing LArSoft code.
- Session 2: Multi-threading and vectorization.
- Multi-threading and vectorization targeting CPUs and grid processing, giving people the background and tools needed to approach the code and start thinking about making their code thread safe, trying to address memory issues, vectorizing, etc.
- Session 3: Long-term vision for LArSoft.
- To discuss ideas and concerns about how LArSoft should evolve with changes to the computing landscape as we move toward the era of DUNE data-taking.
The slides from the speakers can be found on indico. All sessions were recorded. They can be found at: https://vms.fnal.gov/.
Session 1: LArSoft tutorial
Overview and Introduction to LArSoft
 Erica Snider began the LArSoft workshop with an introduction to LArSoft. The LArSoft collaboration consists of a group of experiments and software computing organizations contributing and sharing data simulation, reconstruction and analysis code for Liquid Argon TPC experiments. LArSoft also refers to the code that is shared amongst these experiments. Organizing principle for LArSoft based on a layering of functionality, dependencies.
Erica Snider began the LArSoft workshop with an introduction to LArSoft. The LArSoft collaboration consists of a group of experiments and software computing organizations contributing and sharing data simulation, reconstruction and analysis code for Liquid Argon TPC experiments. LArSoft also refers to the code that is shared amongst these experiments. Organizing principle for LArSoft based on a layering of functionality, dependencies.
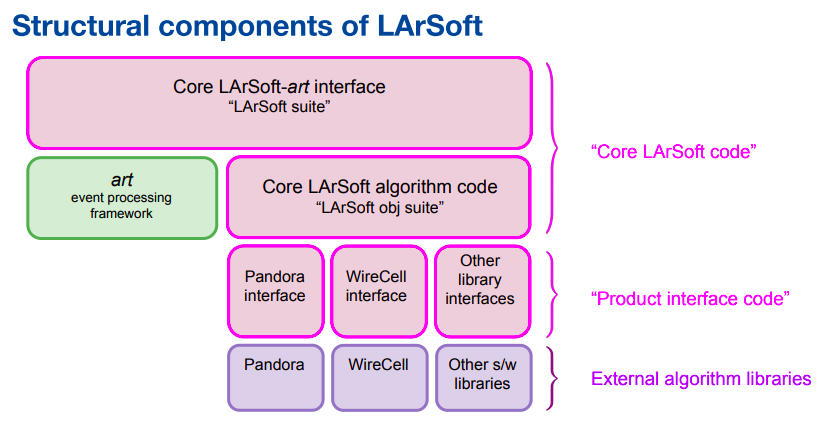
LArSoft is not stand-alone code. It requires experiment / detector-specific configuration. The same basic design pertains to the experiment code. Nothing in core LArSoft code depends upon experiment code.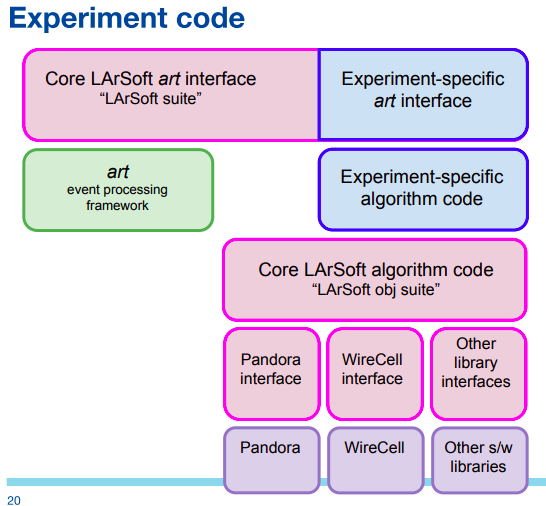
Technical details, code organization
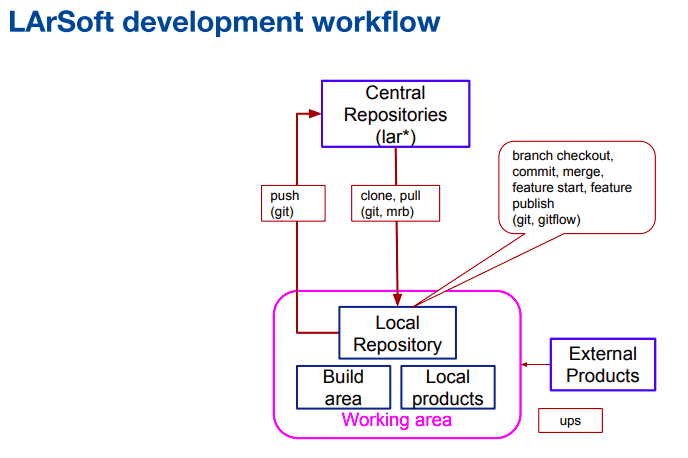
 Saba Sehrish covered repositories, UPS products, setting up and running LArSoft and contributing to LArSoft. There are 18 repositories containing the LArSoft code; each experiment has at least one code repository for detector-specific code.
Saba Sehrish covered repositories, UPS products, setting up and running LArSoft and contributing to LArSoft. There are 18 repositories containing the LArSoft code; each experiment has at least one code repository for detector-specific code.
Simplify your code
 Kyle Knoepfel discussed how code becomes complex. Over time, code becomes larger and larger. Ways to combat this include:
Kyle Knoepfel discussed how code becomes complex. Over time, code becomes larger and larger. Ways to combat this include:
- remove files that you know are not needed
- remove unnecessary header dependencies
- remove unnecessary link-time dependencies
- remove unnecessary functions
- use modern C++ facilities to simplify your code
- reduce coupling to art
Pandora tutorial
Andrew Smith discussed pattern recognition in LArTPC experiments, with Pandora being a general purpose, open-source framework for pattern recognition. It was initially used for future linear collider experiments, but now well established on many LArTPC experiments.
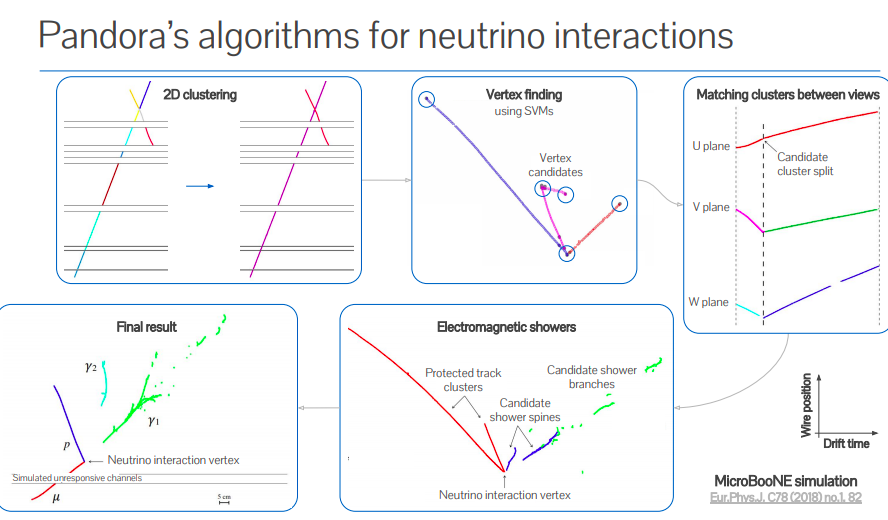
Useful source material on Pandora:
- Multi-day Pandora workshop in Cambridge, UK – 2016
- Talks about how the algorithms work and step-by-step exercises about how you might develop a new algorithm using Pandora.
- LArSoft workshop in Manchester, UK – 2018
- Workshop on advanced computing & machine learning, Paraguay – 2018
- Talks and exercises about running and using Pandora within LArSoft, including tutorials on using Pandora’s custom event display
- Experiment specific resources:
- ProtoDUNE analysis workshop, CERN – 2019
- MicroBooNE Pandora workshop, Fermilab – 2018
Practical guide to getting started in LArSoft
 Tingjun Yang presented a practical guide to getting started in LArSoft. He used ProtoDUNE examples that apply to most LArTPC experiments. A lot can be learn from existing code, talking to people and asking for help on SLACK.
Tingjun Yang presented a practical guide to getting started in LArSoft. He used ProtoDUNE examples that apply to most LArTPC experiments. A lot can be learn from existing code, talking to people and asking for help on SLACK.

How to tag and build a LArSoft patch release
Lynn Garren presented on how to tag and build a patch release by an experiment. MicroBooNE is already doing this. LArSoft provides tools, instructions, and consultation. Up-to-date instructions are available at: How to tag and build a LArSoft patch release.
Session 2: Multi-threading and vectorization
Introduction to multi-threading and vectorization
 Matti Kortelainen discussed the motivation and the practical aspects of both multi-threading and vectorization.
Matti Kortelainen discussed the motivation and the practical aspects of both multi-threading and vectorization.
Two models of parallelism: 1) Data parallelism: distribute data across “nodes”, which then operate on the data in parallel 2) Task parallelism: distribute tasks across “nodes”, which then run the tasks in parallel.
Two threads may “race” to read and write. There are many variations on what can happen.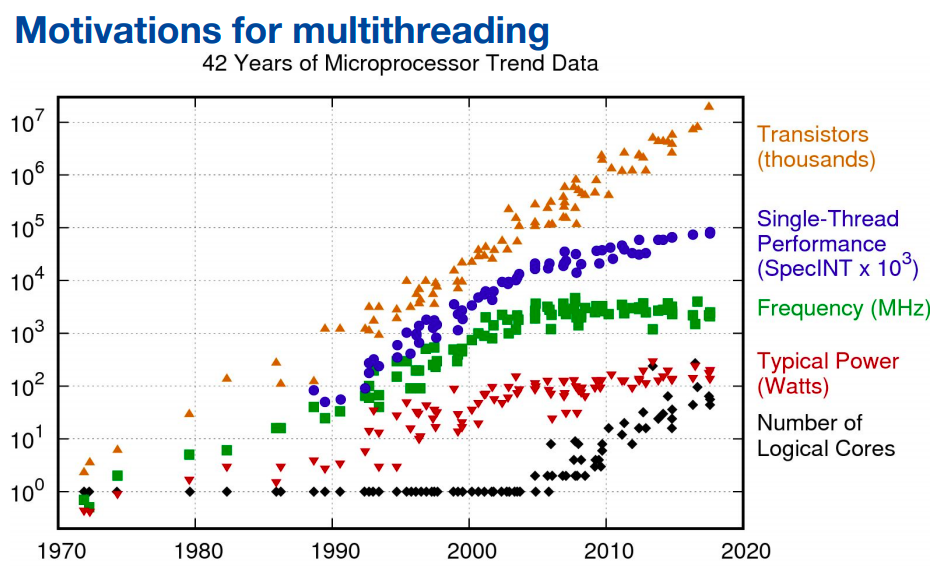
A software thread is the “Smallest sequence of programmed instructions that can be managed independently by a scheduler.” [Wikipedia]
Vectorization works well for math-heavy problems with large arrays/matrices/tensors of data. It doesn’t work so well for arbitrary data and algorithms.
Making code thread-safe
Kyle Knoepfel discussed how to make code thread-safe. The difficulty of this task depends on the context.

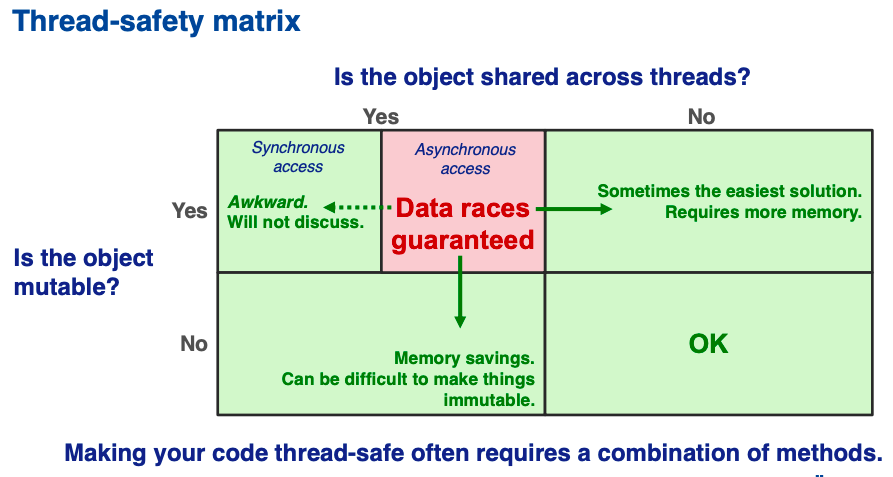
Multi-threaded art
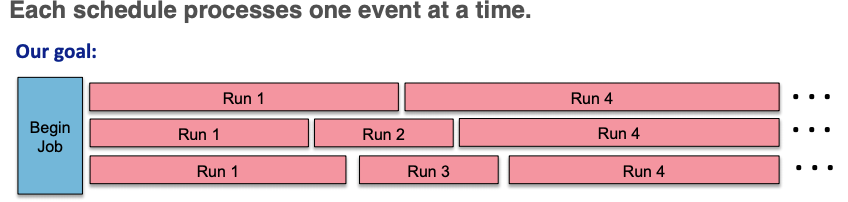
 Kyle Knoepfel described multi-threaded art. Modules on one trigger path may not consume products created by modules that are not on that same path. The design is largely based off of CMSSW’s design.
Kyle Knoepfel described multi-threaded art. Modules on one trigger path may not consume products created by modules that are not on that same path. The design is largely based off of CMSSW’s design.
Experience learning to make code thread-safe
 Mike Wang described his experience with making LArSoft code thread-safe. Except for the most trivial cases, do not expect to be able to hone in on a piece of LArSoft code (such as a particular service) and work on it in isolation in attempting to make it thread-safe. You are dealing with an intricate web of interconnecting and interacting pieces. Understanding how the code works and what it does, tedious as it may seem, goes a long way in facilitating the process of making the code thread-safe, helping avoid errors that will be very difficult to debug.
Mike Wang described his experience with making LArSoft code thread-safe. Except for the most trivial cases, do not expect to be able to hone in on a piece of LArSoft code (such as a particular service) and work on it in isolation in attempting to make it thread-safe. You are dealing with an intricate web of interconnecting and interacting pieces. Understanding how the code works and what it does, tedious as it may seem, goes a long way in facilitating the process of making the code thread-safe, helping avoid errors that will be very difficult to debug.
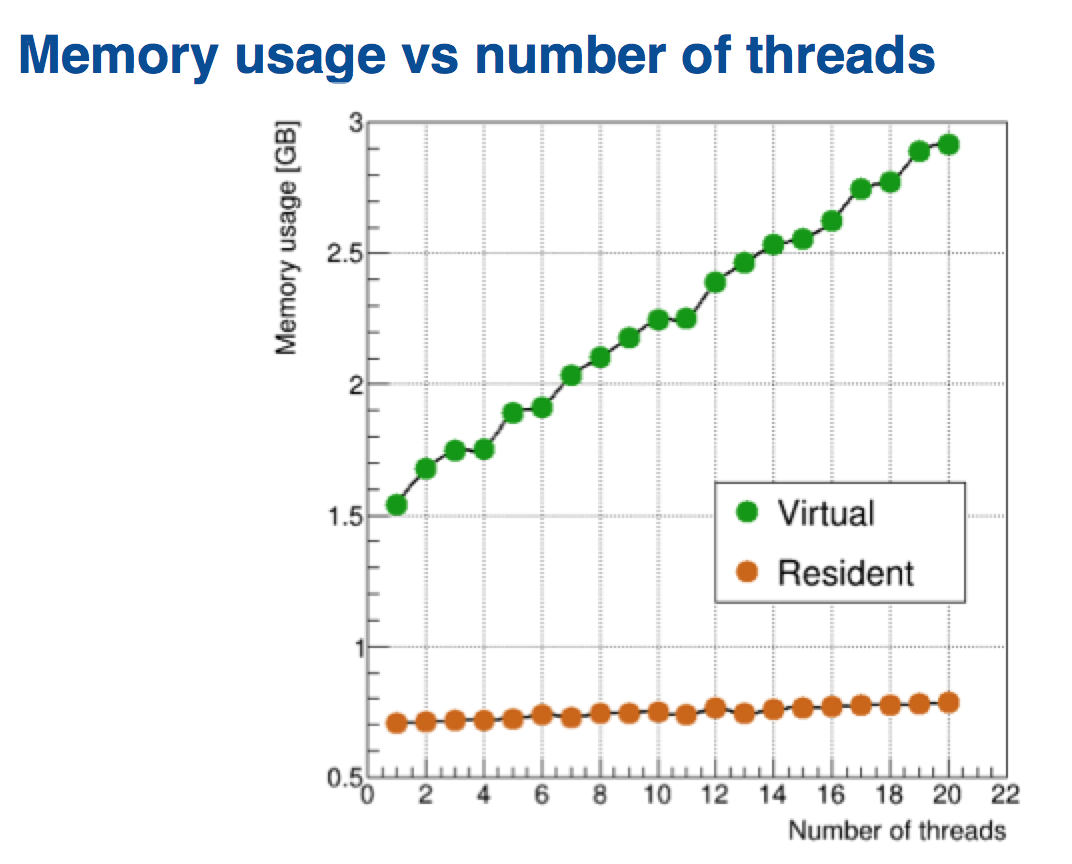
Long-term vision for LArSoft Overview
 Adam Lyon noted that computing is changing (and the change has changed – GPUs over KNLs.) Future: multi-core, limited power/core, limited memory/core, memory bandwidth increasingly limiting. The DOE is spending $2B on new “Exascale” machines.
Adam Lyon noted that computing is changing (and the change has changed – GPUs over KNLs.) Future: multi-core, limited power/core, limited memory/core, memory bandwidth increasingly limiting. The DOE is spending $2B on new “Exascale” machines.
The Fermilab Scientific Computing Division is committed to LArSoft for current and future liquid argon experiments:
- Fermilab SCD developers will continue to focus on infrastructure and software engineering
- Continue to rely on developers from experiments
- Continue to interface to neutrino toolkits like Pandora
- Need to confront the HPC evolution
- Reduce dependency on the framework
Computing in the time of DUNE; HPC computing solutions for LArSoft
 As Giuseppe Cerati noted, technology is in rapid evolution. We can no longer rely on frequency (CPU clock speed) to keep growing exponentially. Must exploit parallelization to avoid sacrificing on physics performance.
As Giuseppe Cerati noted, technology is in rapid evolution. We can no longer rely on frequency (CPU clock speed) to keep growing exponentially. Must exploit parallelization to avoid sacrificing on physics performance.
Emerging architectures are about power efficiency. Technology driven by Machine Learning applications.
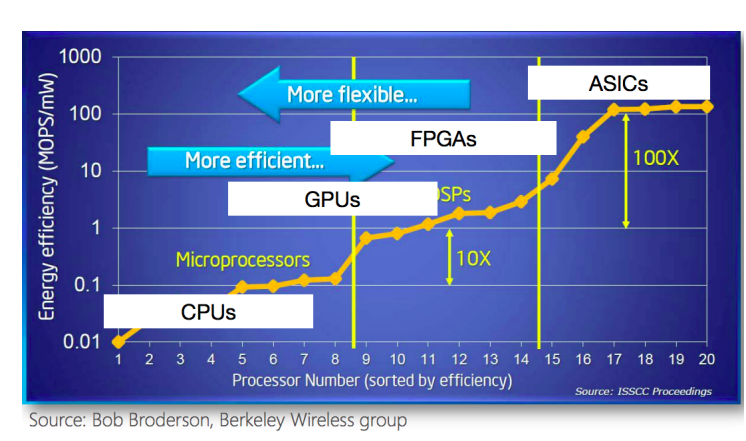
Many workflows of LArTPC experiments could exploit HPC resources – simulation, reconstruction (signal processing), deep learning (training and inference), analysis.
Data management and workflow solutions needed
 Mike Kirby discussed data management and workflow solutions needed in the long-term based mainly on DUNE and MicroBooNE. “Event” volumes for DUNE are an order of magnitude beyond collider events. Already reducing the data volume from raw to just hits.
Mike Kirby discussed data management and workflow solutions needed in the long-term based mainly on DUNE and MicroBooNE. “Event” volumes for DUNE are an order of magnitude beyond collider events. Already reducing the data volume from raw to just hits.
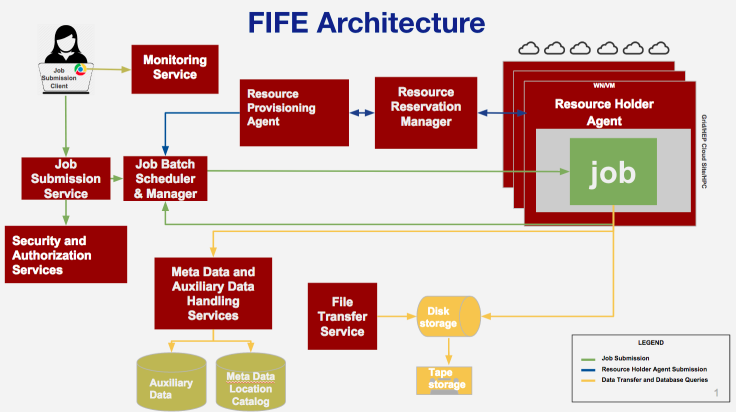
LArSoft framework works wonderfully for processing artroot files – there is a lack of a “framework” for processing non-artroot files (plain ntuples, etc) and this gap could be a problem – CAFAna is actively in use for DUNE and NOvA, but not a fully supported analysis framework.
With multiple Far Detector Modules and more than 100 Anode Plane Arrays possibly readout in a trigger record, the ability to distribute event “chunks” to multiple LArSoft processes/threads/jobs/etc and reassembly into reconstructed events should be explored.
DUNE perspective on long-term vision
 Tom Junk started by discussing the near detector for DUNE. Individual photon ray tracing is time consuming. They are studying a solution using a photon library for ArgonCUBE 2×2 prototype. LArSoft assumes “wire” in the core of Geometry design & APIs to query geometry information. This needs to be changed. Gianluca Petrillo at SLAC designed a generic “charge-sensitive element” to replace the current implementation in a non-distruptive manner. The goal is to run largeant for wire & pixel geometry.
Tom Junk started by discussing the near detector for DUNE. Individual photon ray tracing is time consuming. They are studying a solution using a photon library for ArgonCUBE 2×2 prototype. LArSoft assumes “wire” in the core of Geometry design & APIs to query geometry information. This needs to be changed. Gianluca Petrillo at SLAC designed a generic “charge-sensitive element” to replace the current implementation in a non-distruptive manner. The goal is to run largeant for wire & pixel geometry.
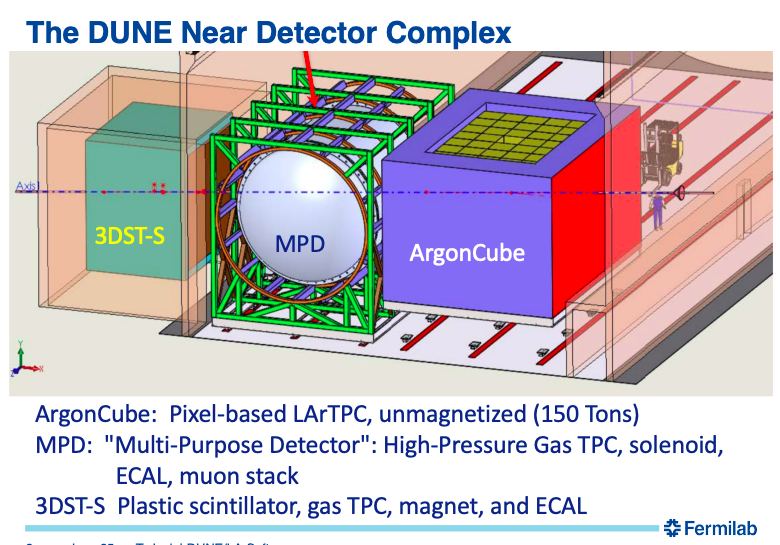
We have some concerns about external source control support. There’s a lot of open-source code out there. Do we have to maintain every piece a DUNE collaborator wants to use?
ICARUS perspective on long-term vision
Tracy Usher pointed out some of the areas where ICARUS is already stressing the “standard” implementation of LArSoft based simulation and reconstruction. ICARUS stands for Imaging Cosmic And Rare Underground Signals. It is the result of some 20+ years of development of Liquid Argon TPCs as high resolution particle imaging detectors from ideas first presented by Carlo Rubbia in 1977.
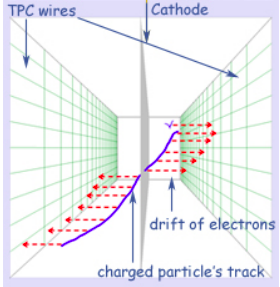
ICARUS has more sense wires than SBND or MicroBooNE, and has 4 TPCs compared to 2 for SBND and 1 for MicroBooNE. ICARUS has horizontal wires, not vertical and they are split. It was originally optimized for detector Cosmic Rays.
Conclusion
Slides are available at https://indico.fnal.gov/event/20453/other-view?view=standard. There were a variety of speakers and topics, from introductory to advanced HPC techniques, enabling people to attend the sections of most interest to them. The quality of the talks was quite high with a lot of new, interesting content which we can now use to update the documentation on LArSoft.org. It will also serve as an excellent basis for discussion moving forward.
Thank you to all who presented and/or participated!


