These can be found in the notes for the March Steering Group meeting at:
All posts by klato
February 2020 Offline Leads Meeting Notes
The February 2020 LArSoft Offline Leads status update was handled via email and a google document.
LArSoft – Erica Snider
At the behest of SCD management, we have investigated a non-Fermilab partner to take the lead in providing a new LArSoft event display (ED). This effort has not panned out, so we are again in the position of having no effort to put into solving the general ED problem. We are now working on next steps, and are considering a completely different strategy to leverage the three most prevalent non-LArSoft EDs to provide a solution a LArSoft/gallery environment.
Licensing and copyright was discussed at the January 28th LArSoft Coordination Meeting. The proposal is to have one file per repository that says, “Copyright 2020 Fermilab for the benefit of the LArSoft collaborating experiments.’, and license all but larpandoracontent and larpandora under the Apache License v2. The larpandora package will be licensed under GPL v3, as is required by the Pandora SDK license.
The project is seeking feedback on the question of whether to continue weekly releases. Based on comments received so far, it appears that the experiments might be open to a less frequent integration release schedule. Offline leads should please advise. Some background:
- The intent of weekly releases was to provide stability for people developing code.
- Because the dependency versioning is tightly coupled to the source code, however, experiments are forced to move their repositories forward as integration releases appear, which in turn typically forces developers to move their working releases forward.
- The weekly update therefore imposes a burden on developers, which at least partially obviates the hoped for stability frequent integration releases were intended to create.
There have been no significant issues reported related to the GitHub migration so far, only minor and easily fixed failures with workflow scripts. Some general guidance was requested for how to collaborate on feature branches, which was provided at the Jan 28th LArSoft Coordination Meeting. We are now attempting to improve the usability of the system through improved tools. A first project in this direction is to provide users and L2 approvers a simple, visual way to assess the status of all pull requests within their projects, or that are otherwise of interest to a developer. The “project” view within GitHub, and OctoBox.com have been discussed as possible solutions.
DUNE – Andrew John Norman, Heidi Schellman, Tingjun Yang, Michael Kirby
LArSoft released hep_hpc v0_12_01, which depends on hdf5 v1_10_5. The protodune analysis package/repository now depends on hep_hpc v0_12_01.
Mike Wang implemented the tensorRT inference client in LArSoft/larreco, which allows larsoft job to evaluate convolutional neural networks on GPUs at a remote server. This has sped up significantly the inference of the networks in the ProtoDUNE reconstruction.
Most of the scripts and code in the dune repositories have been modified to be python3 compatible.
ICARUS – Daniele Gibin, Tracy Usher
Preparations for data taking continue, target date for turning on the High Voltage and seeing first field on data is approximately the beginning of May. The process for cooling and filling is underway now.
Much focus has been on the initial stage which will translate from daq format to LArSoft format. In addition, the initial noise filtering – removing coherent noise – will be done followed by the 1D deconvolution and hit finding using the gaushit module. Effort of the past few months here has been focused on insuring all three steps are thread safe with the result that we have recently been able to demonstrate multi-threaded operation of this stage. We continue to refine this step. An issue is that the testing has been done today using feature branches of several LArSoft packages which are simply defining a few services as “SHARED” rather than “LEGACY”. As we approach real data taking it would be nice for these updates to be part of a LArSoft release so we can take advantage of multi-threaded operation.
There will be strong need for an event display during the commissioning phase which is capable of displaying the full set of RawDigit data at full resolution. With 54,000 channels this is challenging for ICARUS, the LArSoft event display is not capable of performing this task (in particular over a network connection). As such we have worked with Marco Del Tutto to update the event display originally authored by Corey Adams for MicroBooNE – now known as the TITUS event display. This is a combination of python (3) and C++ and is based on the PyQT5 interface. It works unbelievably well for displaying RawDigits at full resolution, in particular the zoom capability is excellent with no delay or redraw, etc. I personally highly recommend this as something that could be adopted by LArSoft.
ICARUS needs to start facing up to logistic issues surrounding calibrations. In particular we need to be setting up several databases to handle calibration constants (e.g. preamplifier gains). The big issue is we have yet to identify a “database expert” on our side but also are not sure the process for interacting on the LArSoft side.
LArIAT – Jonathan Asaadi
No Report
MicroBooNE – Herbert Greenlee, Tracy Usher
No Report
SBND – Roxanne Guenette, Andrzej Szelc
No Report
Please email Katherine Lato or Erica Snider for any corrections or additions to these notes.
January 2020 Offline Leads Meeting Notes
The January 2020 LArSoft Offline Leads status update was handled via a live meeting on January 22 with attendees: Tracy Usher, Andrzej Szelc, Herb Greenlee, Erica Snider, Katherine Lato
- GitHub migration –
- Have started the migration.
- People who have said they will be Level 2 managers (from the experiments) will be in that role. The GitHub side of things is working properly with our scripts.
- We expect that there will be test failures.
- It’s up to the L2 managers to resolve these if related to problems with their experiment. If it’s some other experiment, everyone will be notified and can work with the author to try and resolve it.
- L2 managers should not approve changes that break other experiments before consulting with those experiments. LArSoft will mediate as best we can. We’ll be monitoring the system closely.
- Feature branches cannot be pushed to the central repositories. They need to be shared out of someone’s private area or from a GitHub organization if multiple people are using it.
- Currently trailing white space causes a failure during “code checks”.
- We have a script that strips trailing white space that will fix this. Usually we recommend committing cosmetic changes separately from other changes.
- The script is not context sensitive, so there is a chance that in some cases, using it will change the semantics
- Herb Greenlee – we have production branches. Do we make our own fork?
- They will be migrated. All branches that have names that start with “v” have been migrated. But yes, then you need to make your own fork.
- Tracy – SBND and ICARUS have everything mirrored to GitHub already. Just waiting on LArSoft’s migration.
- Licensing and copyright
- We’ve wanted to do this for some time, and with moving to GitHub it seems like this is a good time.
- We discussed licensing issues with Aaron Sauers of the Office of Partnership and Technology Transfer. He has advised that we can model a copyright on that used by CERN for CMS code, which states, “Copyright CERN for the benefit of the CMS Collaboration”, with appropriate references. He also confirmed that we can license a portion of LArSoft under GPL v3 (the Pandora interface packages that depend explicitly on GPL v3-licensed Pandora SDK), and the balance of LArSoft under Apache v2, our preferred choice, since the balance of the code does not depend in any way on the Pandora interface components. We plan to move forward with licensing under this guidance. Wording will be ‘Copyright Fermilab for the benefit of experiments in the LArSoft Collaboration.’
- Only Pandora was identified as a problem with licenses by the Technology Transfer people.
- Apache v2 is in a class that is least restrictive.
- GPL v3 forces you to make all the code that touches it to be GPL v3. There’s no reason why someone that touches LArSoft code should be forced to be GPL v3.
- Weekly releases vs some alternative
-
- The intent of weekly releases was to provide stability for people developing code. Because the dependency versioning is tightly coupled to the source code, experiments are forced to move their repositories forward as integration releases appear.
- Weekly releases creates a burden. (Not just on LArSoft, but on the experiments as well to keep up.)
- Are the weekly releases valuable? Or will some other model work as well or better? We’d like to have a discussion about this.
- Andrzej would be fine with them less often, but will check.
- Herb thinks could have less, but not just on-demand, since scheduled releases are good.
- Tracy agrees with Herb. Maybe go to having them every other week, the same week at the LArSoft Coordination meetings.
-
- Round-table
-
- Andrzej – SBND
- Doing work parallelizing.
- Getting code running to run on HPC computers, the Theta supercluster at Argonne. They have an allocation there.
- Also running some Director’s Allocation for MicroBooNE stuff. Ran Genie and Corsika- had to change how random numbers are generated, per event, not per job.
- They can run LArSoft out of containers. Have run a reconstruction job. Ran into problem with database web servers. The problem might be on the Argonne side. They don’t allow enough connections to go out to connect to the web servers, not enough slots to go out? Tried to downgrade the number of connections. This caching feature of web servers doesn’t happen since everyone is providing timestamps in nanoseconds so each event has to get its own data rather than sharing. Tried various things, such as down-sampling timestamps. Got it working with a new version that reads a cache file locally, but the feature branch is now two versions higher than the production version.
- Doing work parallelizing.
- Tracy – ICARUS
- Still pushing forward to the idea that ICARUS will be taking data soon. Had a mini-collaboration meeting in mid-January. Expect the end of April before ready to turn on high voltage. Getting the first data out of DAQ system the week of Jan 20th. Starting to show stress points, even reading only 4608 out of 53,000 channels. Bulk of focus is converting data to LArSoft format. Starting to see the first issues, so getting a good head start.
- LArSoft Event display isn’t going to be up to 53,000 channels in ICARUS. So far, they only write out (in MC) the channels that have signal. With larger sets, it’s been clear that running it over the network, it doesn’t work. People have given up on that. Over winter break, worked on Event Display based on QT with Gianluca Petrillo providing an interface to services within a gallery environment. So no longer need to hardcode the geometry. Also enables use with other detectors. Marco Del Tutto has been working on that. Corey Adams and Marco have named their event display “TITUS”. They have released version 1.0 and it has been shown to work with all three of SBND, ICARUS and MicroBooNE detectors. It is not integrated into LArSoft/art proper but, rather, is integrated into gallery. Probably one could change this if desired.
- Umut Kose has continued to develop an Eve based event display. This seems more oriented at the 3D side of things.
- Herb – MicroBooNE
- We are migrating to python 3. There is a “2to3” script that does most of it. Plan on running that on everything. It doesn’t make things backwards compatible — it’s just a straight conversion. He’s trying to make things compatible with 2 and 3 for some stuff. LArCV and LArLite need to work for both python 2 and 3 due to analyses working from existing production branches. This conversion is just for integration releases.
- Question: Noted that python 2 won’t be supported after LArSoft migrates to art 3.05. Is it possible that a security issue with python 2 could arise that would make python 2 unusable, and that would not get patched (which would be a problem for the analyses noted above)? Yes, this is possible, but seems unlikely. Otherwise, things that require Python 2 don’t require a lot of maintenance.
- Andrzej – SBND
-
Please email Katherine Lato or Erica Snider for any corrections or additions to these notes.
November 2019 Offline Leads Meeting Notes
The November 2019 LArSoft Offline Leads status update was handled via email and a google document. Past meeting notes are available at: https://larsoft.org/larsoft-offline-leads-meeting-notes/
LArSoft – Erica Snider
Presented the draft 2020 work plan to SCD management on Nov 7. The presentation noted that the work plan calls for 2 to 3 FTEs of development effort, depending primarily on the effort devoted to multi-threading the code, and the amount of work that the project needs to devote to toward various work items to which the experiments can contribute. The project has about 2 FTEs in the budget. No significant concerns were raised by management.
Testing of using LArSoft with GitHub and the pull request approval workflow has been opened to testing by the experiments. All experiment offline leads and release managers are encouraged to exercise the system, and send comments to the SciSoft team (at scisoft@fnal.gov). Instructions for using the system can be found on the LArSoft wiki under the “Working with GitHub” page (also linked from the “Quick Links”, Using LArSoft”, and “Developing with LArSoft” pages.) Any changes made to the repositories during testing will be deleted prior to the production migration. The current plan is to leave testing open for at least two weeks, but to complete the production migration in early December.
DUNE – Andrew John Norman, Heidi Schellman, Tingjun Yang, Michael Kirby
ProtoDUNE developed a new way to handle raw digits in order to save memory usage. Tom Junk created a tool that decodes protoDUNE raw data and returns it to the caller in the form of vector<raw::RawDigit>. David Adams modified protoDUNE dataprep to use this tool instead of reading digits from the event data store. Other larsoft modules (such as GausHitFinder and various disambiguation algorithms) are modified accordingly to remove hit and raw digit associations. After all the changes, we see a ~10% reduction in memory usage in ProtoDUNE reconstruction job. This new tool allows us to decode raw data one APA at a time and drop raw digits once recob::Wires are made after deconvolution and is applicable to the DUNE far detector where there are 150 APAs per module. More details can be found in #23177.
DUNE made a patch release v08_27_01_01 with the help of Lynn Garren. This release includes artdaq_core bug fixes and a feature to limit tensorflow to only use one CPU to be more grid friendly. The dunetpc v08_27_01_01 is the current release for ProtoDUNE-SP keep-up production.
A new package protoduneana is created. This new package depends on dunetpc and only contains ProtoDUNE analysis code. It is meant to speed up compiling time for people doing analysis.
We are meeting regularly with Erica Snider, Saba Sehrish, and Kyle Knoepfel regarding a project to make the data preparation stages thread safe in order to improve our CPU utilization.
ICARUS – Daniele Gibin, Tracy Usher
No Report
LArIAT – Jonathan Asaadi
No Report
MicroBooNE – Herbert Greenlee, Tracy Usher
No Report
SBND – Roxanne Guenette, Andrzej Szelc
No Report
October 2019 Offline Leads Meeting Notes
10/22/19 Attendees: Tingjun Yang, Thomas Junk, Mike Kirby, David Adams, Erica Snider, Katherine Lato
Agenda: the 2020 work plan and the GitHub migration plan.
The GitHub migration
- The project would like to complete the migration as soon as possible. The infrastructure is ready, but the documentation needs more work, and is critical path for moving into community testing phase.
- The exact procedures for Level 1 and Level 2 need to be worked out.
- Need to know immediately who the level 2 managers are going to be.
- DUNE:
- Level 2 managers:
- Tom Junk
- Tingjun Yang
- Christoph Alt (has already been doing it for another project)
- David Adams
- How many Level 2 managers needed to approve a PR?
- One. Expect that DUNE managers will approve only PRs from / for DUNE. (Exceptions ok if the manager is familiar with the work.)
- Level 2 managers:
- ICARUS
- Tracy Usher (agreed in email after the meeting)
- Emailed other experiments requesting nominees
- DUNE:
- LArSoft will clean the history during the migration.
- Will experiments migrate to GitHub?
- DUNE yes probably yes, in part because Redmine is so slow. Improved performance of GitHub is one of the motivations for the LArSoft move. DUNE has no migration plan yet.
- Noted that there is already a GitHub area, but it doesn’t have TPC code in it. DUNE will think about how to organize repositories
- Will open up the GitHub for testing once the documentation is in place. Would like the testing period to be as long as needed, but as short as possible.
Went through the draft 2020 work plan.
- DUNE would like us to fix the existing event display in advance of having a new event display.
- SPACK.
- Tom ran the MVP, it took all day, took all the memory, but it did work eventually. Not recommended in present state, though.
- We believe this is related to the “concretization” stage, which is known to be slow. Chris Green has been introducing significant optimizations, but having some difficulty getting SPACK owners to accept the changes.
- Tom ran the MVP, it took all day, took all the memory, but it did work eventually. Not recommended in present state, though.
- Pixels
- Check with Mat Muether. Also, Gianluca Petrillo has been working on pixel-related Geometry.
- DUNE suggests we promote magnetic field one to a project.
Please email Katherine Lato or Erica Snider for any corrections or additions to these notes.
September 2019 Offline Leads Meeting Notes
The September 2019 LArSoft Offline Leads status update was handled via email and a google document.
LArSoft – Erica Snider
While we knew that Lynn Garren was retiring the end of January, 2020, we recently learned that Paul Russo is leaving the middle of September. Paul was providing customer support on LArSoft tickets and expertise on multi-threading for LArSoft. We do not yet know what the replacement strategy is.
Due to the changes in available resources, the project needs to shift some responsibilities to the experiments, particularly in the area of code and release management.
- MacOS support – LArSoft support for Mac builds is ending. Could either find someone else to support those builds, or have MacOS developers use SLF containers. (Note that support for those containers will not come from the SciSoft team.)
- GitHub Migration – Need to identify people in experiments for manager roles defined in the pull request workflow. See slides from Patrick Gartung’s presentation Migration of LArSoft repos to GitHub. We will hold additional discussions and provide opportunities for beta testing prior to the migration to GitHub and deployment of the pull request system.
The project has begun the annual process of gathering input from the experiments to inform the 2020 LArSoft work plan. We have met with all the experiments. An initial draft work plan will be discussed at the October Offline Leads meeting.
DUNE – Andrew John Norman, Heidi Schellman, Tingjun Yang, Michael Kirby
ProtoDUNE has started the second production campaign using larsoft/dunetpc v08_27_01. A ProtoDUNE-SP simulation task force is formed to improve detector simulation. The goal is to incorporate the refactorized larg4 and wirecell simulation. DUNE is in the process of transitioning to use tensorflow v1_12_0b with the help of larsoft team. More details in #22504.
ICARUS – Daniele Gibin, Tracy Usher
No Report
LArIAT – Jonathan Asaadi
No Report
MicroBooNE – Herbert Greenlee
MicroBooNE is preparing a major production campaign (MCC 9.1) based on our MCC9 branch (based off larsoft v08_05_00_10). No particular requests to larsoft.
SBND – Roxanne Guenette, Andrzej Szelc
No Report
Please email Katherine Lato or Erica Snider for any corrections or additions to these notes.
July-August 2019 Offline Leads Meeting Notes
The July & August 2019 LArSoft Offline Leads status update was handled via both a meeting (on July 30th) and a google document. People were asked to fill in the information in the document if they couldn’t make the July 30th meeting. Past meeting notes are available at: https://larsoft.org/larsoft-offline-leads-meeting-notes/ Thank you.
LArSoft – Erica Snider
The LArSoft project requests that the experiments provide feedback on the following two items:
- The LArSoft Spack MVP. See the instructions in the email “Announcing Spack / SpackDev MVP1a (“The LArSoft Edition”)” from Chris Green on June 20 to larsoft@fnal.gov.
- This will be the build system for art / LArSoft and the replacement for UPS in the near future. Your feedback is critical to ensure that the final product is easy to use (ie, effective, efficient, intuitive, easy to learn, satisfying). This is our chance to change the outcome.
- This PDF explains the MVP in detail, and how to set it up to evaluate the system.
- Please send any feedback or questions direct to spackdev-team@fnal.gov by July 20th.
- The migration to Genie v3
- Although LArSoft is driving an effort to decouple the version of LArSoft from any specific version of Genie, this is not yet possible. Moreover, once it becomes possible, it is unlikely that any version of Genie v2 will be included.
- We therefore need all experiments to sign off on the v3 migration, or to state their plans with respect to v3 (including any plan to stay at v2.x)
- NOTE: as of July 24, all experiments had signed off on the migration
The project is overseeing a considerable amount of work directed at making various parts of LArSoft thread safe, and in cases, parallelizing specific pieces of code. Some of this coding work will soon be integrated into LArSoft. We expect that a number of services (including experiment-specific provider variants) and various pieces of common code may be affected.
Work on the migration to GitHub is proceeding. More details of what this will look like to end users should be forthcoming over the next couple of months. We are expecting the main parts of the migration to be completed by mid-fall.
DUNE – Andrew John Norman, Heidi Schellman, Tingjun Yang, Michael Kirby
We are working to make the software for the near detector complex work together. This includes a pixel-based liquid-argon component, which will likely use LArSoft directly, a high-pressure gas TPC with an ECAL, called the Multi-Purpose Detector which has a software stack based on art and nutools and thus can run together with larsoft code, and a 3D Scintillator Tracker-Spectrometer. We need to simulate events crossing from one component to another, so a unified GEANT4 simulation is required. Common triggers and event builders will be needed to take data. A workshop was held on July 24 to discuss these issues.
We are also discussing the FD data model at a workshop at BNL on August 14-16. We will discuss databases, data streams, DAQ interfaces, framework and memory management, and of course the event model.
DUNE has discussed the GENIE v3 upgrade. While we are interested in continuing with GENIE v2, we can continue to work with older releases of larsoft and dunetpc. If we absolutely must mix GENIE v2 with newer simulation and reconstruction code, either a patch release or careful accounting of the GENIE systematics weights needs to be done.
We tried the quick-start instructions for the Spack MVP, LArSoft edition and gave some feedback.
ICARUS – Daniele Gibin, (Tracy Usher)
No Report
LArIAT – Jonathan Asaadi
No Report
MicroBooNE – Herbert Greenlee, Tracy Usher
Discussed what MVP meant, does enough to get a feel for it, but can still be changed if needed.
Thinking about when to merge to develop. Things preventing:
- Genie v3 (which is now resolved)
- IO rule, Have a new pid data product which everyone should want. In order to use it, need the IO rule. Waiting for someone to make the change.
SBND – Roxanne Guenette, Andrzej Szelc
No Report
Please email Katherine Lato or Erica Snider for any corrections or additions to these notes.
June 2019 Offline Leads Meeting Notes
Because of the LArSoft Workshop, we didn’t have an Offline Leads meeting in June.
Notes from the workshop can be found at: https://larsoft.org/larsoft-workshop-june-2019/
LArSoft Workshop June 2019
Workshop Overview
The annual LARSoft workshop was held on June 24 and 25 at Fermilab. There were three sessions:
- Session 1: LArSoft tutorial.
- Provide the basic knowledge and tools for navigating, using, writing and contributing LArSoft code.
- Session 2: Multi-threading and vectorization.
- Multi-threading and vectorization targeting CPUs and grid processing, giving people the background and tools needed to approach the code and start thinking about making their code thread safe, trying to address memory issues, vectorizing, etc.
- Session 3: Long-term vision for LArSoft.
- To discuss ideas and concerns about how LArSoft should evolve with changes to the computing landscape as we move toward the era of DUNE data-taking.
The slides from the speakers can be found on indico. All sessions were recorded. They can be found at: https://vms.fnal.gov/.
Session 1: LArSoft tutorial
Overview and Introduction to LArSoft
 Erica Snider began the LArSoft workshop with an introduction to LArSoft. The LArSoft collaboration consists of a group of experiments and software computing organizations contributing and sharing data simulation, reconstruction and analysis code for Liquid Argon TPC experiments. LArSoft also refers to the code that is shared amongst these experiments. Organizing principle for LArSoft based on a layering of functionality, dependencies.
Erica Snider began the LArSoft workshop with an introduction to LArSoft. The LArSoft collaboration consists of a group of experiments and software computing organizations contributing and sharing data simulation, reconstruction and analysis code for Liquid Argon TPC experiments. LArSoft also refers to the code that is shared amongst these experiments. Organizing principle for LArSoft based on a layering of functionality, dependencies.
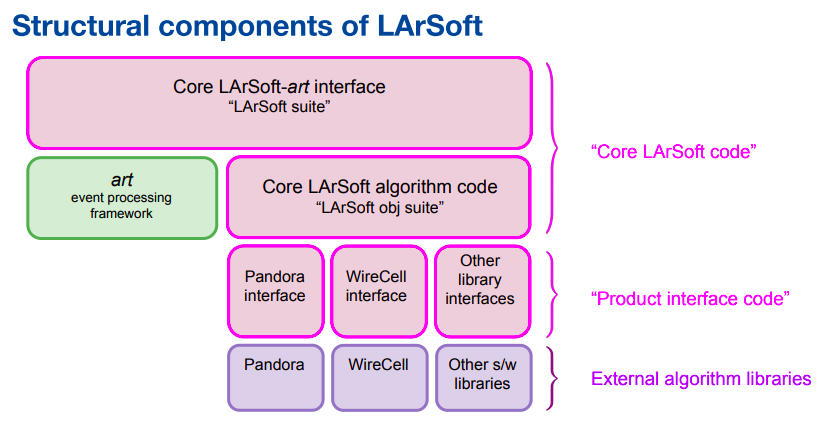
LArSoft is not stand-alone code. It requires experiment / detector-specific configuration. The same basic design pertains to the experiment code. Nothing in core LArSoft code depends upon experiment code.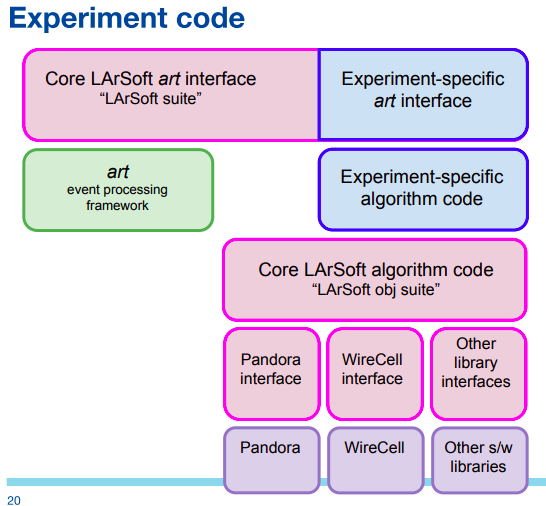
Technical details, code organization
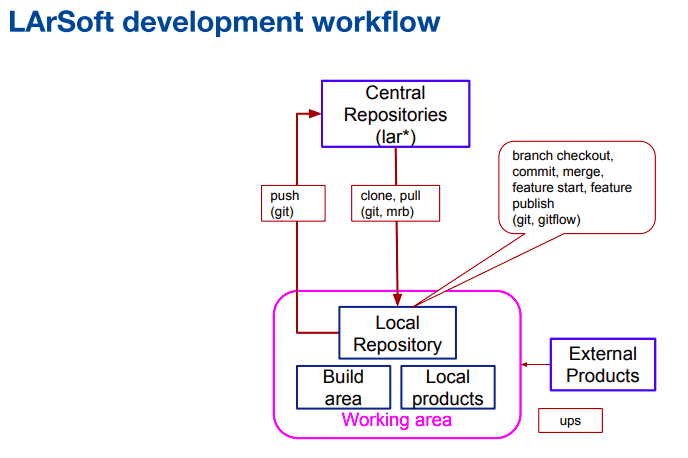
 Saba Sehrish covered repositories, UPS products, setting up and running LArSoft and contributing to LArSoft. There are 18 repositories containing the LArSoft code; each experiment has at least one code repository for detector-specific code.
Saba Sehrish covered repositories, UPS products, setting up and running LArSoft and contributing to LArSoft. There are 18 repositories containing the LArSoft code; each experiment has at least one code repository for detector-specific code.
Simplify your code
 Kyle Knoepfel discussed how code becomes complex. Over time, code becomes larger and larger. Ways to combat this include:
Kyle Knoepfel discussed how code becomes complex. Over time, code becomes larger and larger. Ways to combat this include:
- remove files that you know are not needed
- remove unnecessary header dependencies
- remove unnecessary link-time dependencies
- remove unnecessary functions
- use modern C++ facilities to simplify your code
- reduce coupling to art
Pandora tutorial
Andrew Smith discussed pattern recognition in LArTPC experiments, with Pandora being a general purpose, open-source framework for pattern recognition. It was initially used for future linear collider experiments, but now well established on many LArTPC experiments.
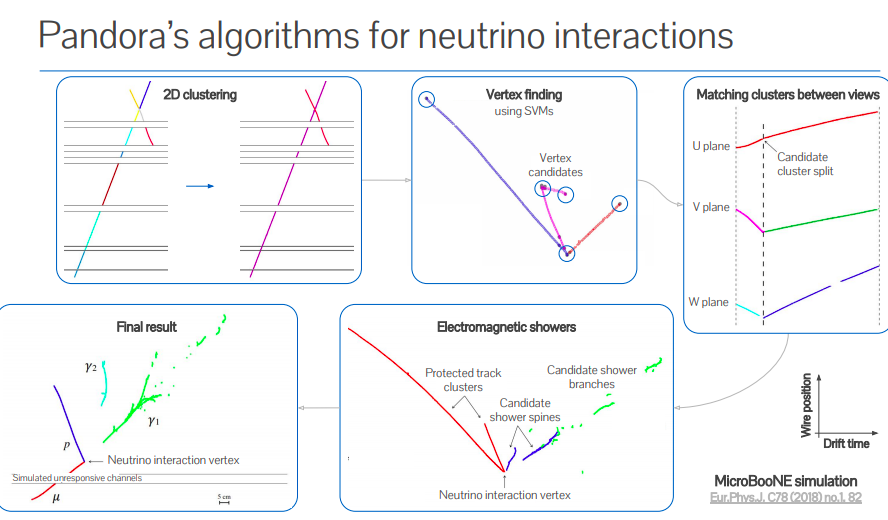
Useful source material on Pandora:
- Multi-day Pandora workshop in Cambridge, UK – 2016
- Talks about how the algorithms work and step-by-step exercises about how you might develop a new algorithm using Pandora.
- LArSoft workshop in Manchester, UK – 2018
- Workshop on advanced computing & machine learning, Paraguay – 2018
- Talks and exercises about running and using Pandora within LArSoft, including tutorials on using Pandora’s custom event display
- Experiment specific resources:
- ProtoDUNE analysis workshop, CERN – 2019
- MicroBooNE Pandora workshop, Fermilab – 2018
Practical guide to getting started in LArSoft
 Tingjun Yang presented a practical guide to getting started in LArSoft. He used ProtoDUNE examples that apply to most LArTPC experiments. A lot can be learn from existing code, talking to people and asking for help on SLACK.
Tingjun Yang presented a practical guide to getting started in LArSoft. He used ProtoDUNE examples that apply to most LArTPC experiments. A lot can be learn from existing code, talking to people and asking for help on SLACK.

How to tag and build a LArSoft patch release
Lynn Garren presented on how to tag and build a patch release by an experiment. MicroBooNE is already doing this. LArSoft provides tools, instructions, and consultation. Up-to-date instructions are available at: How to tag and build a LArSoft patch release.
Session 2: Multi-threading and vectorization
Introduction to multi-threading and vectorization
 Matti Kortelainen discussed the motivation and the practical aspects of both multi-threading and vectorization.
Matti Kortelainen discussed the motivation and the practical aspects of both multi-threading and vectorization.
Two models of parallelism: 1) Data parallelism: distribute data across “nodes”, which then operate on the data in parallel 2) Task parallelism: distribute tasks across “nodes”, which then run the tasks in parallel.
Two threads may “race” to read and write. There are many variations on what can happen.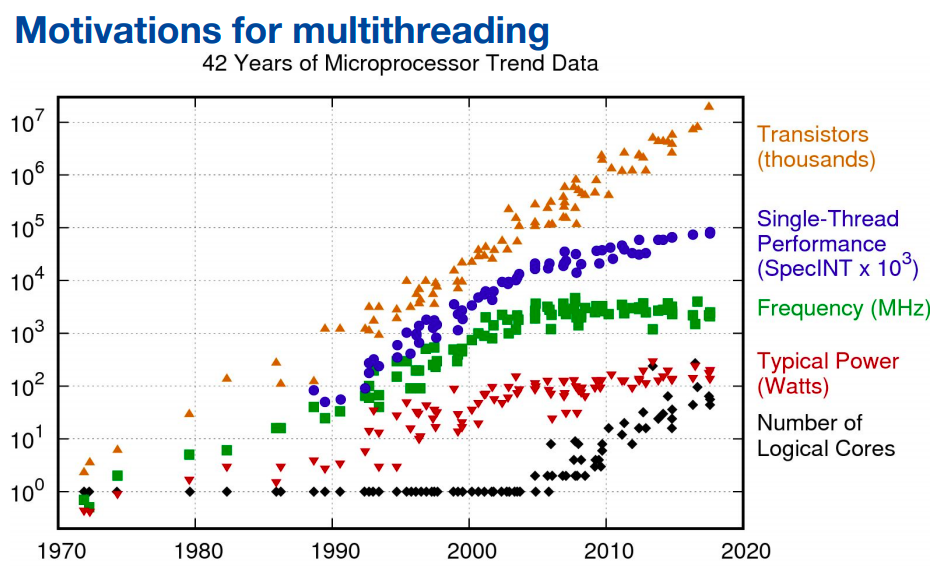
A software thread is the “Smallest sequence of programmed instructions that can be managed independently by a scheduler.” [Wikipedia]
Vectorization works well for math-heavy problems with large arrays/matrices/tensors of data. It doesn’t work so well for arbitrary data and algorithms.
Making code thread-safe
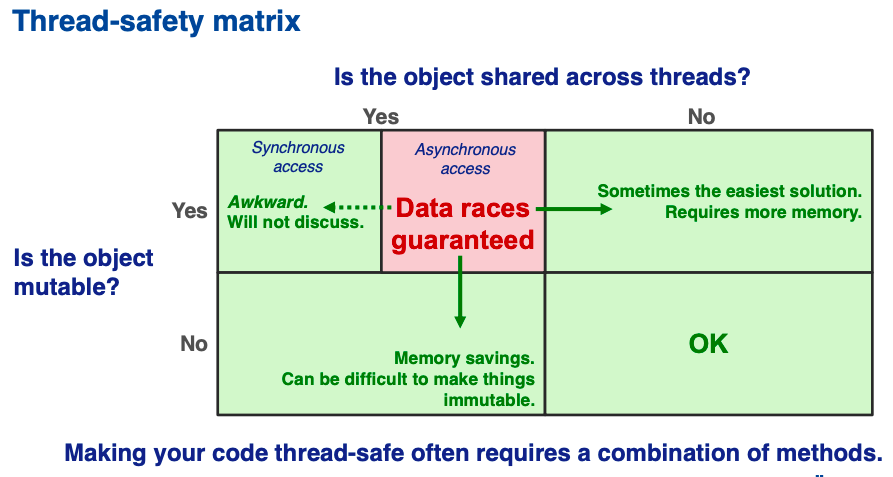
Kyle Knoepfel discussed how to make code thread-safe. The difficulty of this task depends on the context.

Multi-threaded art
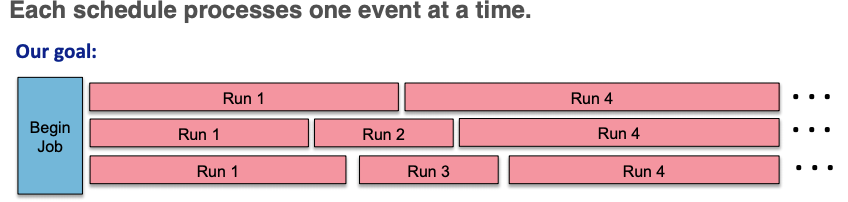
 Kyle Knoepfel described multi-threaded art. Modules on one trigger path may not consume products created by modules that are not on that same path. The design is largely based off of CMSSW’s design.
Kyle Knoepfel described multi-threaded art. Modules on one trigger path may not consume products created by modules that are not on that same path. The design is largely based off of CMSSW’s design.
Experience learning to make code thread-safe
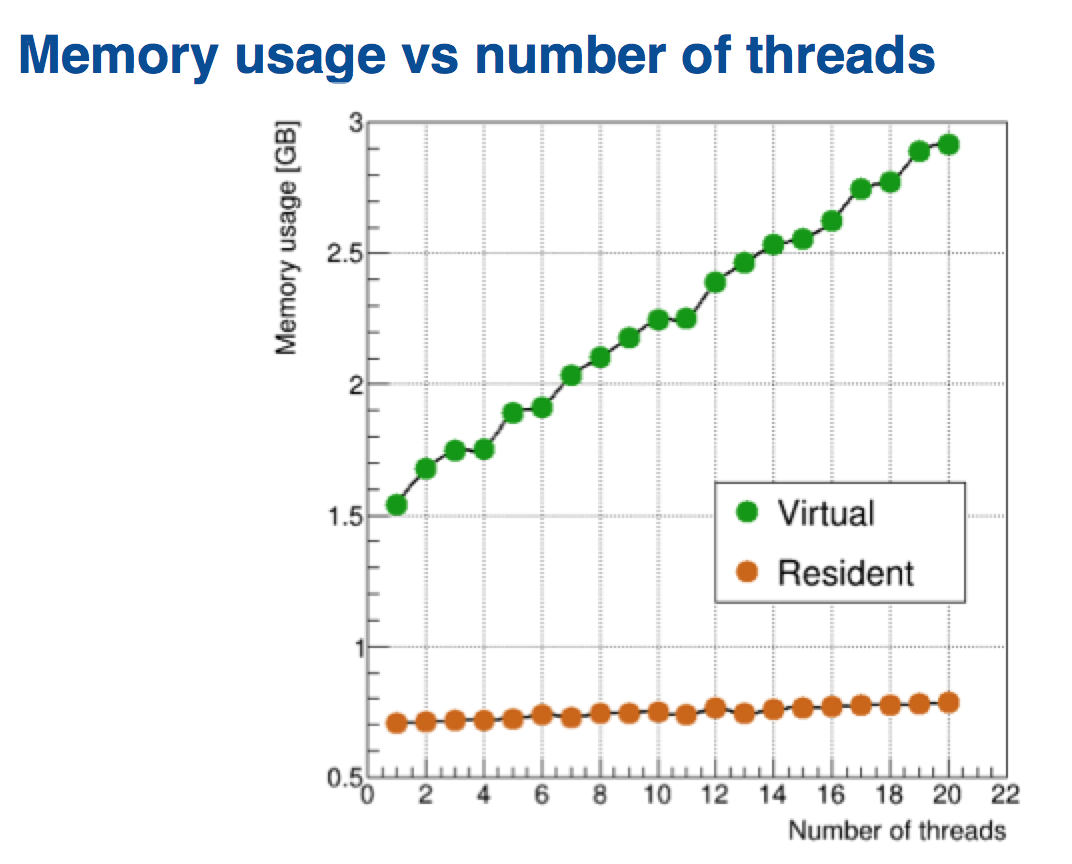
 Mike Wang described his experience with making LArSoft code thread-safe. Except for the most trivial cases, do not expect to be able to hone in on a piece of LArSoft code (such as a particular service) and work on it in isolation in attempting to make it thread-safe. You are dealing with an intricate web of interconnecting and interacting pieces. Understanding how the code works and what it does, tedious as it may seem, goes a long way in facilitating the process of making the code thread-safe, helping avoid errors that will be very difficult to debug.
Mike Wang described his experience with making LArSoft code thread-safe. Except for the most trivial cases, do not expect to be able to hone in on a piece of LArSoft code (such as a particular service) and work on it in isolation in attempting to make it thread-safe. You are dealing with an intricate web of interconnecting and interacting pieces. Understanding how the code works and what it does, tedious as it may seem, goes a long way in facilitating the process of making the code thread-safe, helping avoid errors that will be very difficult to debug.
Long-term vision for LArSoft Overview
 Adam Lyon noted that computing is changing (and the change has changed – GPUs over KNLs.) Future: multi-core, limited power/core, limited memory/core, memory bandwidth increasingly limiting. The DOE is spending $2B on new “Exascale” machines.
Adam Lyon noted that computing is changing (and the change has changed – GPUs over KNLs.) Future: multi-core, limited power/core, limited memory/core, memory bandwidth increasingly limiting. The DOE is spending $2B on new “Exascale” machines.
The Fermilab Scientific Computing Division is committed to LArSoft for current and future liquid argon experiments:
- Fermilab SCD developers will continue to focus on infrastructure and software engineering
- Continue to rely on developers from experiments
- Continue to interface to neutrino toolkits like Pandora
- Need to confront the HPC evolution
- Reduce dependency on the framework
Computing in the time of DUNE; HPC computing solutions for LArSoft
 As Giuseppe Cerati noted, technology is in rapid evolution. We can no longer rely on frequency (CPU clock speed) to keep growing exponentially. Must exploit parallelization to avoid sacrificing on physics performance.
As Giuseppe Cerati noted, technology is in rapid evolution. We can no longer rely on frequency (CPU clock speed) to keep growing exponentially. Must exploit parallelization to avoid sacrificing on physics performance.
Emerging architectures are about power efficiency. Technology driven by Machine Learning applications.
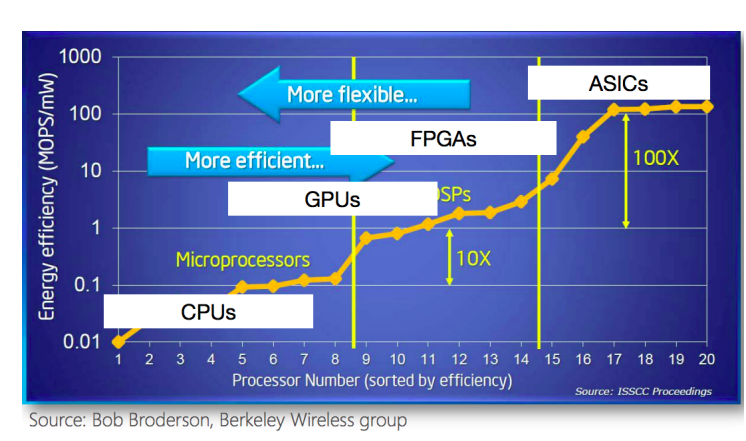
Many workflows of LArTPC experiments could exploit HPC resources – simulation, reconstruction (signal processing), deep learning (training and inference), analysis.
Data management and workflow solutions needed
 Mike Kirby discussed data management and workflow solutions needed in the long-term based mainly on DUNE and MicroBooNE. “Event” volumes for DUNE are an order of magnitude beyond collider events. Already reducing the data volume from raw to just hits.
Mike Kirby discussed data management and workflow solutions needed in the long-term based mainly on DUNE and MicroBooNE. “Event” volumes for DUNE are an order of magnitude beyond collider events. Already reducing the data volume from raw to just hits.
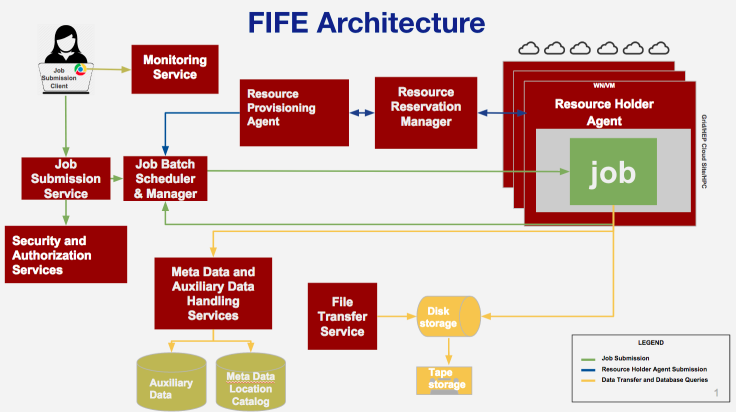
LArSoft framework works wonderfully for processing artroot files – there is a lack of a “framework” for processing non-artroot files (plain ntuples, etc) and this gap could be a problem – CAFAna is actively in use for DUNE and NOvA, but not a fully supported analysis framework.
With multiple Far Detector Modules and more than 100 Anode Plane Arrays possibly readout in a trigger record, the ability to distribute event “chunks” to multiple LArSoft processes/threads/jobs/etc and reassembly into reconstructed events should be explored.
DUNE perspective on long-term vision
 Tom Junk started by discussing the near detector for DUNE. Individual photon ray tracing is time consuming. They are studying a solution using a photon library for ArgonCUBE 2×2 prototype. LArSoft assumes “wire” in the core of Geometry design & APIs to query geometry information. This needs to be changed. Gianluca Petrillo at SLAC designed a generic “charge-sensitive element” to replace the current implementation in a non-distruptive manner. The goal is to run largeant for wire & pixel geometry.
Tom Junk started by discussing the near detector for DUNE. Individual photon ray tracing is time consuming. They are studying a solution using a photon library for ArgonCUBE 2×2 prototype. LArSoft assumes “wire” in the core of Geometry design & APIs to query geometry information. This needs to be changed. Gianluca Petrillo at SLAC designed a generic “charge-sensitive element” to replace the current implementation in a non-distruptive manner. The goal is to run largeant for wire & pixel geometry.
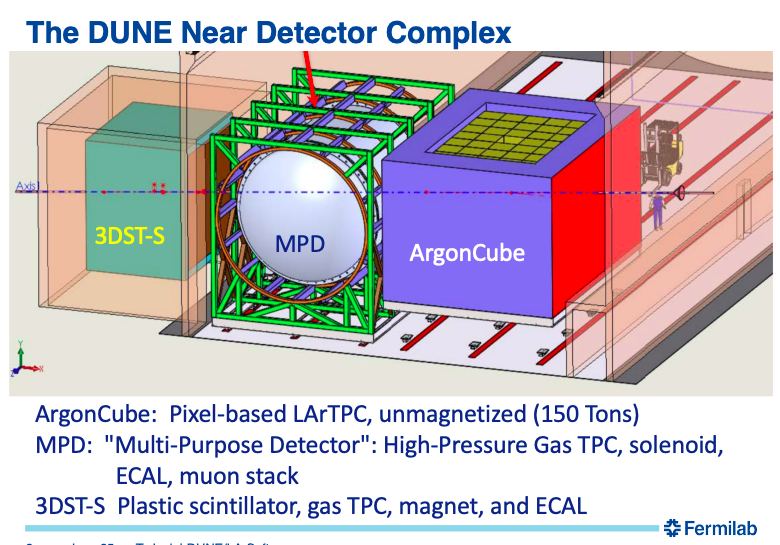
We have some concerns about external source control support. There’s a lot of open-source code out there. Do we have to maintain every piece a DUNE collaborator wants to use?
ICARUS perspective on long-term vision
Tracy Usher pointed out some of the areas where ICARUS is already stressing the “standard” implementation of LArSoft based simulation and reconstruction. ICARUS stands for Imaging Cosmic And Rare Underground Signals. It is the result of some 20+ years of development of Liquid Argon TPCs as high resolution particle imaging detectors from ideas first presented by Carlo Rubbia in 1977.
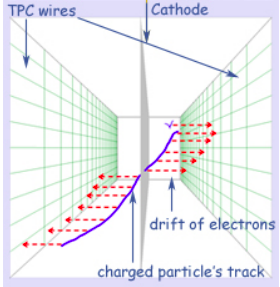
ICARUS has more sense wires than SBND or MicroBooNE, and has 4 TPCs compared to 2 for SBND and 1 for MicroBooNE. ICARUS has horizontal wires, not vertical and they are split. It was originally optimized for detector Cosmic Rays.
Conclusion
Slides are available at https://indico.fnal.gov/event/20453/other-view?view=standard. There were a variety of speakers and topics, from introductory to advanced HPC techniques, enabling people to attend the sections of most interest to them. The quality of the talks was quite high with a lot of new, interesting content which we can now use to update the documentation on LArSoft.org. It will also serve as an excellent basis for discussion moving forward.
Thank you to all who presented and/or participated!



May 2019 Offline Leads Meeting Notes
The May 2019 LArSoft Offline Leads status update was handled via email and a google document.
LArSoft – Erica Snider
- Planning for the LArSoft Workshop 2019 is nearly complete. The agenda and speakers can be found on indico here: https://indico.fnal.gov/event/20453/other-view?view=standard
- A “minimally viable” Spack/SpaceDev-based build and development environment for LArSoft is under initial testing within the SciSoft team. The purpose of the current product is to provide sufficient functionality to allow meaningful testing and feedback on Spack and SpackDev. The plan is to distribute this version for testing and comment from the experiments once sufficient documentation and fixes for known bugs are available.
- LArSoft has been asked to upgrade to python 3 which requires dropping SLF6. Seeking feedback from experiments and users.
DUNE – Andrew John Norman, Heidi Schellman, Tingjun Yang, Michael Kirby
- No Report
ICARUS – Daniele Gibin, (Tracy Usher)
- Experience with running our last MC challenge exposed some issues with memory and cpu time for simulation and reconstruction of events. Primarily this is in the TPC reconstruction but there are also problems in the PMT simulation/reconstruction (primarily associated with the photon lookup library) and the CRT. Work has been underway to try to address issues with the TPC reconstruction first and this has led to a new workflow for both simulation and reconstruction where the signal processing is broken into groups by TPC (there are four TPCs in ICARUS) and then pattern recognition is done by Cryostat (there are two cryostats in ICARUS). The detector simulation then changes to output four collections of RawDigits, one per TPC and this is meant to emulate what the DAQ folks tell us they will do when we begin data taking.
This breakup should enable the ability for some amount of parallelization of the processing, also with each instance of a particular processing module using less memory.
In addition to this, there is also effort underway to reformat some of the signal processing modules to allow for vectorization techniques now available (or soon to be available?) in art. We hope to be in a position to test soon.
- Recent improvements to the photon lookup library have led to an explosion in the memory requirements once read back from a disk file, at last check taking some 6.5 GB of memory. This library is not only more detailed but extends now to both Cryostats. Gianluca Petrillo has implemented some code in LArSoft which will try to make use of symmetries in the library to reduce memory, but this needs to be tested. If this cannot make a significant reduction then it will be necessary to look at alternatives.
- The BNL team is starting preliminary effort to port the WireCell toolkit to ICARUS for simulation and noise filter/2D deconvolution. Currently targeting integration in time for commissioning.
- Finally… there is significant effort in developing machine learning techniques for 3D reconstruction using ICARUS as the current target platform. Toward that end the current LArSoft workflow produces 3D SpacePoints (using “Cluster3D”) which are then siphoned off into the deep learning effort’s workflows using a new version of the LArCV package (now LArCV3). It would be highly useful if this were an “official” LArSoft package, importantly including proper makefile set up to enable builds in the standard LArSoft framework (e.g. using mrb).
LArIAT – Jonathan Asaadi
- No Report
MicroBooNE – Herbert Greenlee, Tracy Usher
- No Report
SBND – Roxanne Guenette, Andrzej Szelc
- No Report
Please email Katherine Lato or Erica Snider for any corrections or additions to these notes.