Note: Information moved to: https://larsoft.org/important-concepts-in-larsoft/geometry/ on 12/13/21.
Thanks to the help of Erica Snider, Gianluca Petrillo and Thomas Junk, we have an updated Geometry description available in the LArSoft wiki here. The geometry package contains classes related to the geometry representation such as planes, TPCs, cryostats, etc. The LArSoft geometry provides descriptions of the physical structures and materials in the detector. Some important specifiable parameters in the detector geometry include:
the position of the detector relative to the beam
the structure and material properties of the cathode planes
where individual photon detectors are
the placement of wires and the distance between them within a plane
the distance between the wire planes
the details of the material surrounding the cryostat
the composition of the overburden
transformations between coordinate systems attached to various elements and global coordinates
The geometry also provides a mapping between sensing elements such as wires or strips and DAQ channels.
LArSoft release 6.28 changed the geometry to support dual-phase TPCs, which caused several assumptions to be removed or to change:
the drift direction is no longer assumed to be along x, but can be on any axis
the projection of a point on a plane is no longer assumed to have coordinates (y,z)
views no longer are assumed to measure a coordinate growing with z
the outer plane cannot be assumed to have drift coordinate 0 (same as drift distance)
When updating code, understanding the assumptions at the time the code was written may help explain why certain options were chosen.
For more information, please go to the LArSoft wiki here.
Attendance: Erica Snider, Katherine Lato, Wes Ketchum, Thomas Junk, Herb Greenlee, Robert Sulej
Round Robin – we went over the open issues (see end of notes), then went around the room.
LArSoft – Erica Snider
DIscussed Geant4 work and how it has been rescoped. (see issue 2 below)
Don’t know the target for new build system. Isn’t on the critical path for any experiments at this time.
Floating Point Exceptions – agreed to fix these. They are almost always bugs and should be fixed. Often the first one fixed reveals more.
Documentation standard – please remind developers to follow them. Should ctskelgen also work for tools? (Feature request?)
Tensor Flow is high priority – had meetings on 8/16 and 8/17 to deal with issues involved.
Gianluca is leaving in September of 2018. Not much news on replacement except that a dedicated developer isn’t likely. Feedback from experiments — having a dedicated developer like Gianluca has been invaluable. Someone thinking fulltime about things has been useful for collaborators for things they aren’t familiar with, developing best practices, code maintenance, etc. Having a developer go through common code to ensure the code is done, and done better. ICARUS relied on a small group of experts who aren’t tasked with doing that, so having a developer who can do the technical work relieves the load on the experiment and collaboration. When the solution is useful for more than one experiment, it’s good to have that solution be professional. It would be useful to have a team of developers work on the needs of the collaboration.
DUNE – Thomas Junk
Dune TPC is getting big and the build is slow, not a LArSoft issue, but Tom mentioned it.
ICARUS – Daniele Gibin not available but Wes Ketchum reported.
Could use support in getting things going on the grid and build. Lynn has given guidance, including looking at other experiment’s. Note, Patrick might be able to help with this. And Vito.
LArIAT – Jonathan Asaadi
No Report
MicroBooNE – Herbert Greenlee, Wesley Robert Ketchum
Working on getting openCV, LArCV as a UPS product. Don’t know if they need assistance from LArSoft since they’re working on integration.
ProtoDUNE – Robert Sulej
Just finished a meeting about Tensor Flow, that is high priority.
Interested in the material we already covered in this meeting, Geant 4. They met with Hans and he said he would try to develop a data product they could use in dual phase. It is also high priority for them. They need the data product before they need the rest of the factorization.
SBND – Andrzej Szelc
Report via email:
We finally got our basic geometry working. We have launched our first larger scale production using it (this is still single file .gdml, not the advanced version mentioned below) and will be debugging any problems that arise before we mount full scale production in next weeks.
In parallel, we are working toward testing that our optical simulation is working (also needed for full scale production).
Next month we should have validation results of tests + some idea of how that all works with large scale production.
We have had some first problems with running reco jobs – which might be due to disk space on grid nodes. We’re trying to understand what happened there.
Finally, we have identified a person that will take over geometry management, so might come back to the multiple file design.
Open issues from previous meetings:
From 3/22/17 meeting: Since SBND has been trying to include files inside GDML, have run into problems. Gianluca has been helping debug this. New version of ROOT may be a solution.
4/18/17 update: The version of root used by LArSoft has changed a few times over the last few weeks. Andrzej Szelc said they haven’t looked into this because they were focusing on getting the basic geometry in. Once that is done, will look at this and hope the new ROOT version may have fixed it. So, no ticket has been written yet (to ROOT or LArSoft) about this as waiting on whether it is still an issue.
5/25/17 update – still waiting.
6/14/17 update – Once SBND gets the latest version of ROOT in, they’ll see if this fixes the issue.
7/27/17 update – SBND is still finalizing the new Geometry idea – expert moving. Once this is done, we have a student starting up that could follow up on whether the bugs are gone in the newest version of ROOT. In the meantime Gianluca with Vito’s help is putting sbndcode in the continuous integration framework – this will be very useful.
8/16/17 – have basic geometry working. Still debugging before mounting full scale production.
2. From May: Feedback at a recent SBN analysis meeting on proposed restructuring of G4 simulation step was that these were potentially very important changes. Is it possible to see all of this in place this summer for ICARUS large-scale processing and potentially MicroBooNE processing campaign? Along with the work itself, how one updates/does the backtracking remains an unanswered question: not technically difficult, but could imply significant changes in downstream code based on how it is done. This may take another or a few more people working on it to really see it through.
8/16/17 update – Up until June, thought could get it done by mid-summer. The original plan was to incrementally replace parts of the LArG4 code with the updated Geant4 functionality and interfaces. But it looks like it is easier to do a full replacement. Since we changed the scope, we’re awaiting a good estimate on completion.
A question about the design arose, which was whether the ionization and scintillation modeling is downstream of the energy deposition, or embedded in the Geant4 stepping. ICARUS (and presumably other experiments) would like to be able to run ionization and scintillation, and all other downstream simulation in a separate job from the energy deposition simulation. It is not clear whether this is possible if the ionization and scintillation is done by Geant4. We (LArSoft) believe this will be possible with the re-factored code, but should be verified with Hans. Will set up a meeting with Hans, Wes and Erica when he’s back to clarify design details and get a reasonable end-date or if additional resources are needed.
3. From 6/14/17 meeting: MicroBooNE asked about how to give credit to authors, experiments and institutions for LArSoft code written.
We committed to presenting a proposed documentation template for header files at a LArSoft Coordination Meeting. (This was done on 6/27/17).
LArSoft has a place to give author credit for algorithms and services on larsoft.org – as well as in the code itself. This is not being done enough, so suggest a multi-prong education campaign to encourage people to sign their name on the code they write and to contribute to the http://larsoft.org/doc-algorithms/ page. This will be highlighted in a LArSoft Coordinate Meeting with follow up but this needs to be done by all experiments, not just LArSoft.
Presented proposal at June 27 Coordination Meeting. The action items from that discussion
Add institution and experiment to the template
Publish the template on a web page
What are the plans from the experiments to push this practice out to the code?
Recommend adding template documentation whenever code is updated?
Need to provide an environment variable so that the template to ctskelgen points to a file with the above field. https://cdcvs.fnal.gov/redmine/issues/17426 – redmine issue for that work assigned to Erica.
The July Offline Leads ‘meeting’ was handled via email and a google document. We heard from over half the experiments, not bad for a July. Next meeting is live.
LArSoft Report – Erica Snider
Floating Point Exceptions policy decision. After a discussion at the 6/27/17 LArSoft Coordination meeting led by Herb Greenlee, we concluded we don’t want to ignore FPEs. Thomas Junk has been tracking down where exceptions occur under the umbrella milestone of https://cdcvs.fnal.gov/redmine/issues/17047. Summary of the discussion at the June 27 Coordination Meeting:Continue reading July 2017 LArSoft Offline Leads Meeting Notes→
Attendees:
Andrzej Szelek, Wes Ketchum, Thomas Junk, Herb Greenlee, Erica Snider, Katherine Lato
Round robin:
LArSoft – Erica and Katherine discussed the process of follow-up with issues, and how if it’s a ‘real issue,’ we’d like the Offline Leads to create the redmine issue so we know who to follow-up with. We then went through some of the current issues–but broke to have time for the round robin reports.
DUNE – Tom Junk
They’re dealing with a number of little things that are experiment-specific.
DAQ people from ProtoDUNE will give them error codes as well as other information per tick which is a lot of error information. Erica suggests putting it in a parallel structure so it’s easier to navigate. There will be some experiment-specific code that will have to know about it.
DUNE is interested in when the LArG4 restructure is done.
For best practices in DUNE, they are currently telling people to follow art’s and LArSoft’s. Note, LArSoft is happy to take suggestions to improve our recommended practices. This discussion related to an issue that art proposed a technical solution and a justification following best practices.
ICARUS– Daniele Gibin
No report
LArIAT – Jonathan Asaadi
No report
MicroBooNE – Wesley Robert Ketchum and Herb Greenlee
Wes has spoken with Hans and Wes has follow up to do with Hans on integrating with the LArG4 restructure work. Wes put this on hold but will try to find the time for this.
Both ICARUS and SBND state they would like to have separate storing of simulated energy depositions as an output of geant4, something that for use in event mixing and potentially translation of events within and among detectors (for systematic studies). I know other experiments are interested too.
There are basic modules for electron and photon (based on library) propagation, but it’s likely that more effort will be needed here (from other experiments or the project.) NEST currently has hooks to the G4 geometry/materials and his cannot cleanly be handled right now, for instance. This would also represent a doubling up of data, as energy depositions are stored in a slightly different way as part of the sim channels. I think design and infrastructure work may be necessary to evolve or consolidate how the information is stored and how things are properly backtracked. Overall, this deserves a solid review if here’s any significant changes planned, as I think we would prefer to do any change like this once and have it be stable for some time.
MicroBooNE spokes are concerned about giving credit to authors of code who contribute to LArSoft. And to experiments. During the discussion, we also mentioned including the institution. LArSoft has a place to give author credit for algorithms and services on larsoft.org – as well as in the code itself. This is not being done enough, so suggest a multi-prong education campaign to encourage people to sign their name on the code they write and to contribute to the http://larsoft.org/doc-algorithms/ page. This will be highlighted in a LArSoft Coordinate Meeting with follow up but this needs to be done by all experiments, not just LArSoft. The reason people should want to do this is that they may want a job reference some day and people need to be able to tell what they did.
Code should contain 5 pieces of information every time 1) Name, 2) from experiment, 3) from institution, 4) date 5) Good information about what this code does. Code was written by X author from experiment from institution X. It’s important to not imply that the code is for a given experiment–some people will assume that means it doesn’t apply to them.
LArSoft can and should supply templates, but how do we ensure that people use them? Use the template-generators and then you get a header with information defined. We should update those templates to include from experiment, and institution. Should be skeleton for generic files like algorithms, phython macros, tools, an effort to update them would be good, not just art-specific. But one problem is that most people develop on their laptops, so may not use the template generators. Still, we can take this as an issue — create skeletons for a document section in the top of header files for module code, algorithms, services. Post these to redmine. Make them part of skelton generators. May need a better name. Perhaps the first step is to talk about this at a Coordination meeting, and get a team from multiple experiments to work on this.
Also talked about automatic ways to determine who is doing work such as commit counter — and then do something with it. Like poking them to add something to larsoft.org.
SBND – Andrzej Szelek –
Very interested in Hans’ work, especially with wavelength and other things that changes the propagation times. The effect would show up in the photon library, but Hans hasn’t said he has functions that would replace the photon library. They’re interested in what is going on and are interested in anything that will speed things up. They are using the index of something now. The timing simulation takes that into account.
A large part of the simulation is in, thanks for all the help with that from Erica and Gianluca. They were using standard GEANT4 projections taking for granted, but they forgot to include it so are building a branch to put that in. They uncovered a bug in GEANT4 timing. There’s code in LArG4 that is copied verbatim from GEANT4. The charge loss is calculated and the first step is wrong, so the timing can be slightly off. It affects the distribution. They have a hacky fix that looks at this and fixes the velocity of the first step if need be. A systematic fix would be better, but GEANT4 says it works for them. There is something in GEANT4 that prevents it from being a bug for them, but it is for us. We are moving to GEANT4 photon propagation.
When they were trying to do a demo using event display, the mouse function didn’t work.
Issues from previous Offline Leads meetings to follow-up on and new issues from 6/14/17 meeting.
From May 2017: How to handle different interaction time hypotheses for particles in an event.
Background: In ProtoDUNE, there can be four or more measurements of the time of an interaction, associated beam arrival time information, cosmic-ray counter hits, photon-detector hits, and a diffusion-based measurement. Some of these may have mis-associations and multiple candidate times reconstructed. This is probably just an analysis issue — what we want to do with these candidate times. The obvious thing is to use them to calibrate timing offsets in the detector, but there may be other uses, such as improving the reconstruction of particles broken in different volumes for other uses.
6/14/17 update – The attendees discussed possible infrastructure work related to how to handle different interaction times, with some clarification of terms. All agreed that “t0” is not a good name, but that’s what we have for it. This value needs to be attached to different things, so the current practice is to create associations between t0 objects as needed, and let experiment analyses deal with the details. Tom (who brought this up last month) agreed that attempting to centralize any further handling of this information within LArSoft is not needed. This issue can be closed.
From May 2017: Feedback at a recent SBN analysis meeting on proposed restructuring of G4 simulation step was that these were potentially very important changes. Is it possible to see all of this in place this summer for ICARUS large-scale processing and potentially MicroBooNE processing campaign? Along with the work itself, how one updates/does the backtracking remains an unanswered question: not technically difficult, but could imply significant changes in downstream code based on how it is done. This may take another or a few more people working on it to really see it through.
After 6/14/17 consult with Hans on the current status – Work in Geant4 has been completed, and now need to re-structure and adapt LArG4. This portion of the work is being tracked in the above issue. The new version of LArG4 will use the artg4 toolkit, and will expose the energy deposition after particle tracing through the LAr as a new interface layer. The energy deposition will be performed via step limiting, so will eliminate the current usage of voxelization within a parallel geometry. Modeling of ionization and photon statistics will continue to be performed via some interchangeable unit that is independent of the rest of the code. Charge and photon transport will be factored into new modeling layers, where the latter is optionally performed by Geant4. Charge transport modeling will deliver arrival times and positions at a predetermined plane (e.g, a readout plane, a grid plane, etc). The current thinking is that details of how charge transport occurs within the anode region will be handled separately. An alternative is to allow Geant4 to deliver charge to each of the anode planes. This scheme provides for charge deposition with the anode region, but would complicate adapting the simulation to different readout schemes (e.g., 90-degree strips as in DP detectors, or readout pixels as proposed for DUNE ND). The photon transport modeling would deliver arrival times at photo-detectors after all wave-shifting. This scheme allows for complete Geant4 modeling of photon transport, including all wave-shifters (which are defined in the detector geometries), or alternatively, parameterized transport outcomes. The choice between the two options would be made via fhicl options (either disabling Geant4 photon transport and enabling the factored transport model, or visa versa). A modified backtracking scheme comes along with all this.
From 4/19/17 meeting: DUNE wants something added to hit to store things for dual-phase. Robert Sulej is working on this with dual phase person. Additional hit parameters are used only in the event display. Having them inside hit would make code more simple. Having the parameters separated is reasonable as well since they are specific to dual phase. In the code branch we are developing there is a working solution to keep hit parameters in a separate collection, with no need for Assns.
5/25/17 update – need to follow up to see if keeping the hit parameters in a separate collection works.
6/14/17 update – Concluded that the current scheme of using additional data products for DUNE is adequate.
From 4/19/17 meeting: Presentation from student on CNN and adversarial network? According to Robert Sulej, it is possible to think of making such machine-learning-based filter for the detector/E-field response simulation, but it is a future work. They are working now on the idea rather to provide data-driven training set for the CNN model preparation. Need time to understand the results to tell what is the limitation of the tool and what isn’t.
5/25/17 update – This has been on the schedule for a coordination meeting, and has been postponed at the request of the authors
6/14/17 update – No update
From 3/22/17 meeting: Since SBND has been trying to include files inside GDML, have run into problems. Gianluca has been helping debug this. New version of ROOT may be a solution.
4/18/17 update: The version of root used by LArSoft has changed a few times over the last few weeks. Andrzej Szelc said they haven’t looked into this because they were focusing on getting the basic geometry in. Once that is done, will look at this and hope the new ROOT version may have fixed it. So, no ticket has been written yet (to ROOT or LArSoft) about this as waiting on whether it is still an issue.
5/25/17 update – still waiting.
6/14/17 update – Once SBND gets the latest version of ROOT in, they’ll see if this fixes the issue.
From 6/14/17 meeting: MicroBooNE asked about how to give credit to authors, experiments and institutions for LArSoft code written. Have updated the recommendation on documenting code at http://larsoft.org/important-concepts-in-larsoft/design/. We will also present a proposed documentation template for header files at a LArSoft Coordination Meeting. LArSoft has a place to give author credit for algorithms and services on larsoft.org – as well as in the code itself. This is not being done enough, so suggest a multi-prong education campaign to encourage people to sign their name on the code they write and to contribute to the http://larsoft.org/doc-algorithms/ page. This will be highlighted in a LArSoft Coordinate Meeting with follow up but this needs to be done by all experiments, not just LArSoft.
Please let us know if there are any corrections or comments to these meeting notes.
Panagiotis Spentzouris welcomed participants and said the emphasis for LArSoft is on moving forward, improving technologies. Looking at the agenda, that’s what LArSoft is doing. As Panagiotis said, “Improvements in performance have been accomplished … Looking at the path of this project, things are on track.” Panagiotis’ welcome is available as an audio file below.
Erica provided an introduction to the workshop, explaining that the reason for the workshop is that, “We want things that make our work easier, that help us produce better code and make our code run faster/more efficiently.” The workshop explores parallel computing, Continuous Integration, a new build system for art/LArSoft called Spack, debugging and profiling tools. Erica’s presentation is available as slides or as a video.
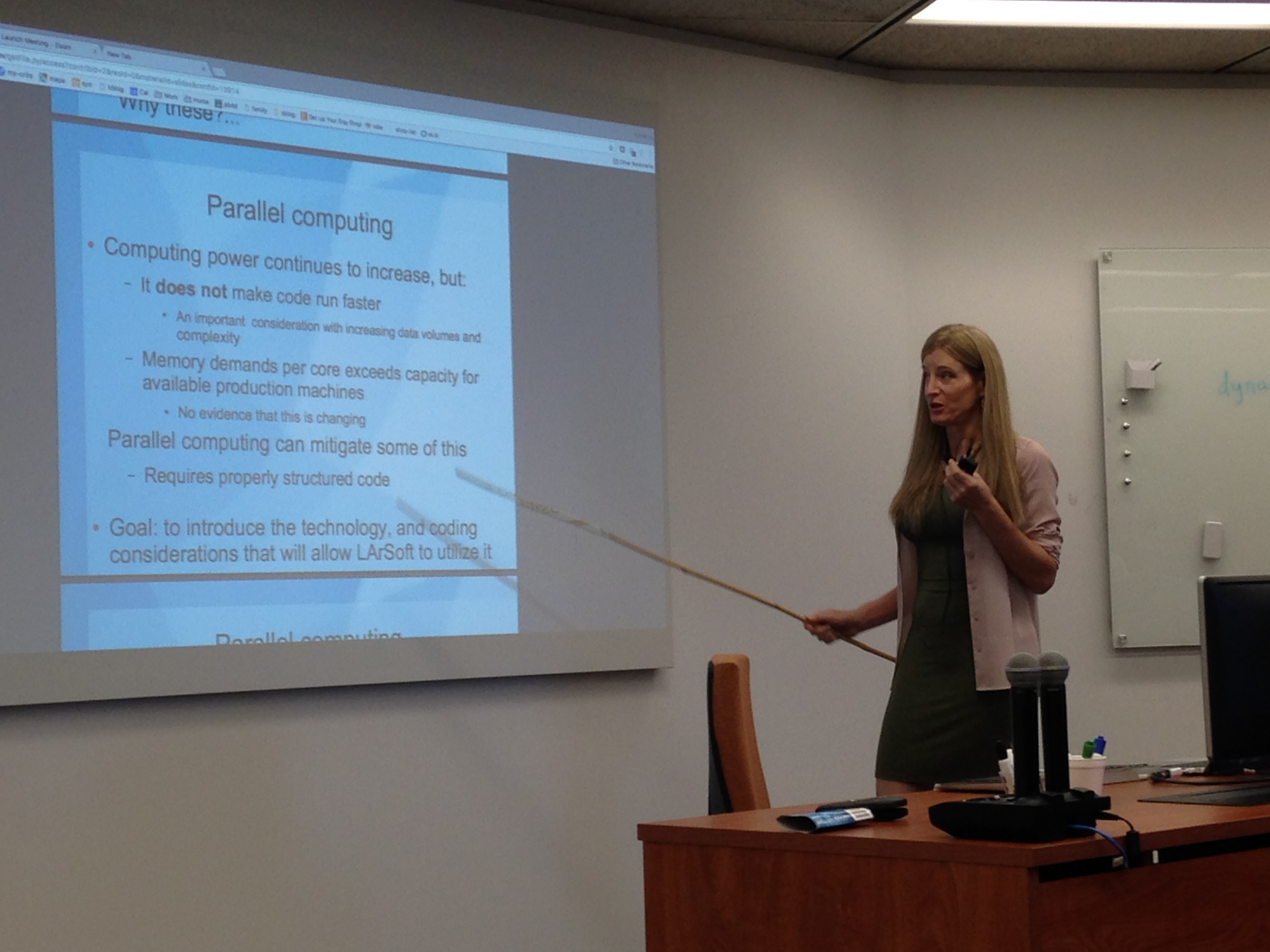
Chris explained that multi-threading is threads that can interact through shared memory, whereas multiple processes cannot. Multi-threading speeds up the program and enables the sharing of resources within the program itself. This is needed because computing hardware trends are that CPU frequencies no longer increase. Included in the presentation were examples of race conditions and that there are no benign race conditions. There are different levels of thread safety for objects:
thread hostile – not safe for more than one thread to call methods even for different class instances
thread friendly – different class instances can be used by different threads safely
const-thread safe – multiple threads can call const methods on the same class instance
thread safe – multiple threads can call non-const methods on the same class instance
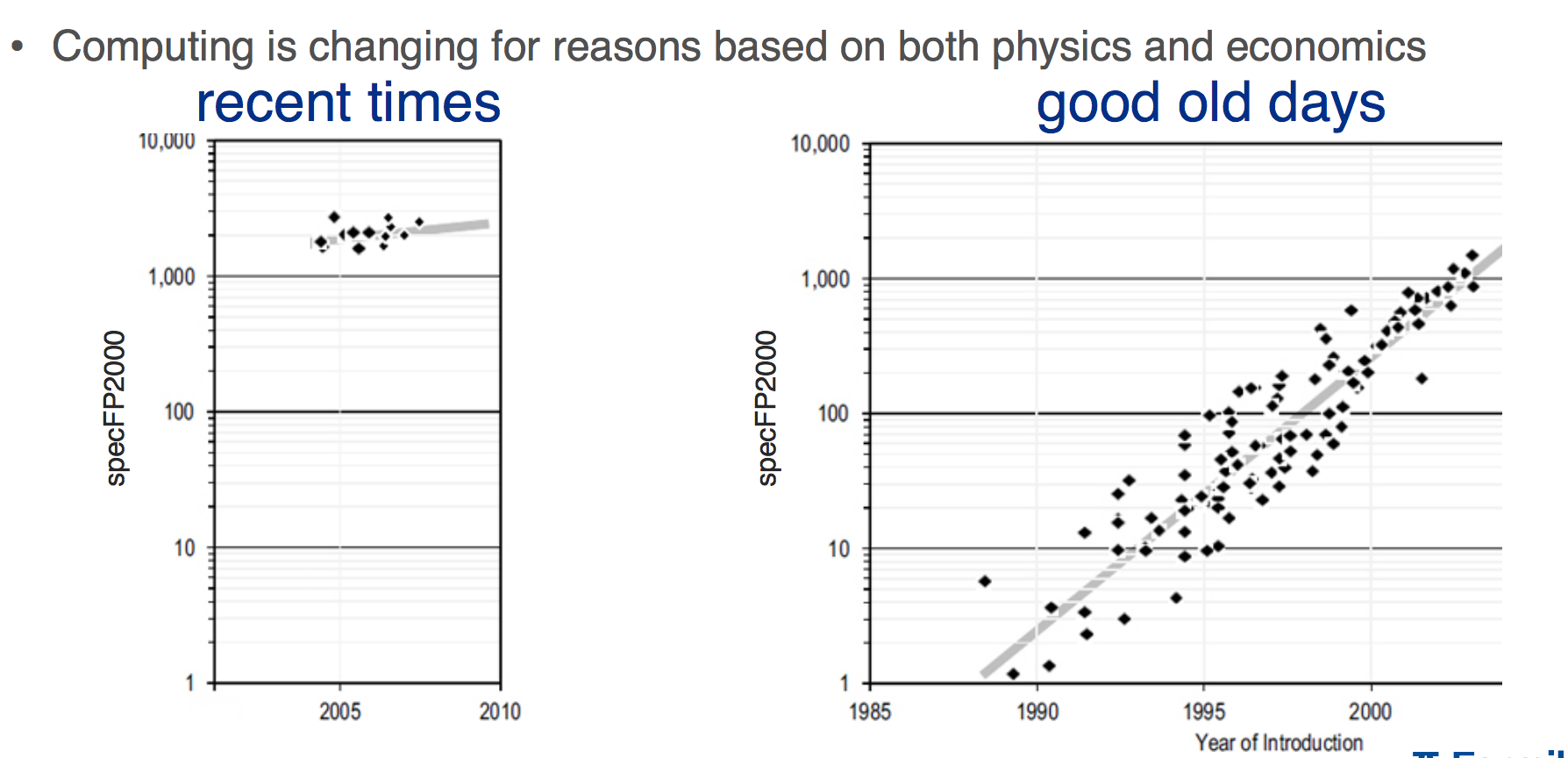
Single Instruction Multiple Data (SIMD) – a single instruction performs the same operation on multiple data items. We used to be able to just wait for hardware improvements to get faster, but that isn’t true anymore, as the following shows.
SIMD instructions have the potential to improve floating point performance two to 16 times. Jim showed examples of taking advantage of SIMD instructions, encouraging people to look at the different libraries that do this. Many widely-available math libraries include SIMD intrinsic support. He showed a LArSoft roofline analysis performed by Giuseppe Cerati using Intel Advisor.
Jim’s presentation is available as slides or a video.
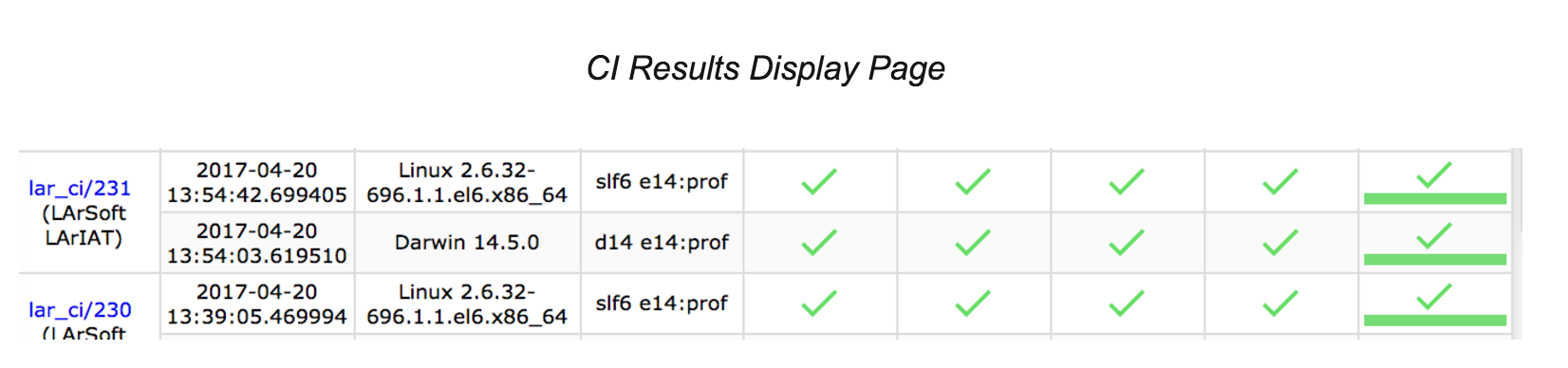
Continuous Integration is a software engineering practice in which changes in a software code are immediately tested and reported. The goal is to provide rapid feedback to help identify defects introduced by code changes as soon as possible. Vito covered how to run CI and obtain results with detailed examples. The questions included wanting to see a sample script, so Vito brought up the Redmine page: https://cdcvs.fnal.gov/redmine/projects/lar_ci/wiki.
Vito’s pesentation is available as slides or a video.
LArsoft and art are moving to the Spack and SpackDev based build system. This system does not have one-for-one replacements for existing tools. Spack is a package manager designed to handle multiple versions and variants – https://spack.io/ – https://github.com/LLNL/spack. The original plan was to have a full demo at this workshop, but Spack development is behind schedule, so we could only explore Spack functionality. To try Spack, go to https://github.com/amundson/spackdev-bootstrap
Jim’s presentation is available as slides or a video.
Paul explained the basics of using the gdb debugger to find and fix errors in code. The compiler must help the debugger by writing a detailed description of their code to the object file during compilation. This detailed description is commonly referred to as debugging symbols.
Paul’s presentation is available as slides or a video.
Soon Yung gave an introduction to computing performance profiling with an overview of selected profiling tools and examples. Performance tuning is an essential part of the development cycle. Performance benchmarking quantifies usage/changes of CPU time and memory (amount required or churn). Performance profiling analyzes hot spots, bottlenecks and efficient utilization of resources. Soon also gave profiling results of the LArTest application with IgProf and Open|Speedshop.
Soon’s presentation is available as slides or a video.
Feedback
Comments include:
I found most of it useful. I’m fairly new to all of this, so it was mostly all new, useful information.
Increasing the portions for beginners or have a stand alone workshop for beginners.
More hands-on, interactive tutorials for the audience, even if it means installing some software/programs in advance.
I would like to have some topics which may be aimed towards participants who are less-than experts with the hope that us physicists can be more than just second-rate programmers.
Mostly; I thought the topics were good choices but would have preferred it to be a bit more hands-on.
I think these topics were the right ones; maybe even more on running on HPC resources next time.
This ‘meeting’ was handled via email and a google document. We heard from all but one experiment, SBND. If there are no objections, we may try this every other month. So we’ll meet in June, but do the google doc for July.
LArSoft – Erica Snider
The highest project work priorities are: LArSoft Workshop planning; continuation of association usability project work (which should be coming to a close soon); infrastructure and design adaptations for ProtoDUNE SP/DP and ICARUS; deployment of the new Spack-based build system; and re-factoring of LArG4. Other short term priorities can be found in the 2017 work plan document (May 2 update) here: https://indico.fnal.gov/conferenceDisplay.py?confId=14198
As noted at the May 23 Coordination Meeting, details of the Spack / SpackDev based build system are not entirely finalized. In particular, details of the user interface are still open to changes based on feedback from beta testing and during presentations. We hope to have a deployment plan and schedule update at the next LArSoft Coordination Meeting. There will be a detailed discussion at the LArSoft Workshop. It seems likely that deployment will occur after the workshop.
LArSoft has been contacted by ArgonCube to discuss possible integration strategies for pixel readout LArTPCs.
ICARUS/MicroBooNE collaborators have re-written MicroBooNE signal processing classes to use art tools with a common abstract interface. This work is similar to that done by DUNE (David Adams) for ADC simulation and response functions. The project will help to coordinate these efforts in order to consolidate on a common set of interfaces to be used across all experiments for these processing steps. At that point, experiments will have the option of moving their now proprietary code into LArSoft to create a library of signal processing tools.
The LArSoft workshop will have both profiling and debugging tutorials based on user request.
DUNE – Thomas R Junk
We are focusing on getting ready for the ProtoDUNE run. The Track-shower CNN looks very promising but takes substantial CPU to run. Installation of TensorFlow is intended to help this issue.
We would like to thank Erica for giving the LArSoft tutorial at the DUNE collaboration meeting.
One thing which cropped up recently is how to handle different interaction time hypotheses for particles in an event. In ProtoDUNE, there can be four or more measurements of the time of an interaction, associated beam arrival time information, cosmic-ray counter hits, photon-detector hits, and a diffusion-based measurement. Some of these may have mis-associations and multiple candidate times reconstructed. This is probably just an analysis issue — what we want to do with these candidate times. The obvious thing is to use them to calibrate timing offsets in the detector, but there may be other uses, such as improving the reconstruction of particles broken in different volumes for other uses.
LArSoft response: “We should have a discussion at a LArSoft Coordination Meeting, or at a dedicated meeting to discuss strategies for handling this issue. It might be “just an analysis issue”, but to the extent that it potentially affects various position-dependent corrections, it might also need to be handled more rationally within the production reconstruction phases. Either way, it would be helpful to develop a consensus within the community as to how we will approach the problem.”
ICARUS – Daniele Gibin
The ICARUS spokesperson is Carlo Rubbia.
LArIAT – Brian J. Rebel
Brian has taken on the role of Technical Coordinator for the SBND and is stepping away from the LArSoft coordination. He will be available for consultations, but will no longer be able to contribute to any updates to the code or participate in the meetings.
Jonathan Asaadi will be fulfilling the role of Offline Lead for LArIAT.
MicroBooNE – Wesley Robert Ketchum
Gave overview of (previously) proposed restructuring of G4 simulation step at recent SBN analysis meeting, decoupling GEANT4 pieces with “propagation” pieces for ionized electrons. Feedback was that these were potentially very important changes, for both technical reasons (potential for reduction in memory footprint on grid, fewer rounds of simulation reprocessing, flexibility in combining different types of events) and physics reasons (ability to take energy depositions from neutrino interaction and translate them within one detector, or even from one detector to another to study systematics). Spoke today with Hans on where that stands and we are on same page with the other G4 restructuring work. Would be good to see all of this in place on the time scale of this summer for ICARUS large-scale processing and potentially MicroBooNE processing campaign: is that possible? Along with the work itself, how one updates/does the backtracking remains an unanswered question: not technically difficult, but could imply significant changes in downstream code based on how it is done. This may take another or a few more people working on it to really see it through.
LArSoft response: “The original schedule for this work was not met, and has not yet been updated. We will work with Hans to make that happen. Until then, we cannot comment on when the project will be completed, except to note that there has been steady progress on all of the underlying tasks. The project and schedule are being tracked in issue 14454.
SBND Roxanne Guenette, Andrzej Szelc
No report
Items from Offline Leads Meeting on 4/19/17 to follow-up on:
DUNE wants something added to hit to store things for dual-phase. Robert Sulej is working on this with dual phase person. Additional hit parameters are used only in the event display. Having them inside hit would make code more simple. Having the parameters separated is reasonable as well since they are specific to dual phase. In the code branch we are developing there is a working solution to keep hit parameters in a separate collection, with no need for Assns.
5/25/17 update – need to follow up to see if keeping the hit parameters in a separate colletion works.
Presentation from student on CNN and adversarial network? According to Robert Sulej, it is possible to think of making such machine-learning-based filter for the detector/E-field response simulation, but it is a future work. They are working now on the idea rather to provide data-driven training set for the CNN model preparation. Need time to understand the results to tell what is the limitation of the tool and what isn’t.
5/25/17 update – This has been on the schedule for a coordination meeting, and has been postponed at the request of the authors
From 3/22/17 meeting: Since SBND has been trying to include files inside GDML, have run into problems. Gianluca has been helping debug this. New version of ROOT may be a solution.
4/18/17 update: The version of root used by LArSoft has changed a few times over the last few weeks. Andrzej Szelc said they haven’t looked into this because they were focusing on getting the basic geometry in. Once that is done, will look at this and hope the new ROOT version may have fixed it. So, no ticket has been written yet (to ROOT or LArSoft) about this as waiting on whether it is still an issue.
5/25/17 update – still waiting.
Please let us know if there are any corrections or comments to these meeting notes.
Various studies have shown that the later in a project errors are found, the more it costs to fix them.[1][2][3] The Continuous Integration (CI) approach of software development adopted by LArSoft can save time by finding errors earlier in the process. As Lynn Garren noted, “Using CI allows you to test your code in the complete LArSoft environment independent of other people, which can save you time.” Another important benefit is noted by Gianluca Petrillo, “By using the CI system, I gain confidence that my code changes will not break other people’s work since the tests in the CI system will notify me if something went awry.”
The LArSoft Continuous Integration system is the set of tools, applications and machines that allows users to specify and automate the execution of tests of LArSoft and experiment software. Tests are configured via text files in the various repositories and are launched in response to an http trigger initiated manually by a user or automatically on every git push command to the develop branch of the central repositories. Arguments in the trigger specify run-time configuration options such as the base release to use, the branch within each repository to build (the develop branch by default), and the test “suite” to run, where each suite is a workflow of tests specified in the configuration files. Prior to each test, the new code is built against the base release. The CI system reports status, progress, test results, test logs, etc. to a database and notifies users with a summary of results via email. A web application queries the database to display a summary of test results with drill-down links to detailed information.
As Erica Snider said, “People focus on the testing needed for their particular experiment. One benefit of our CI system is that, every time a change is made, it automatically tests the common code against all of the experiment repositories, then runs the test suites defined by each of the experiments. This allows us to catch interoperability problems within minutes after they are committed.”
There have been a number of updates to CI in recent months aimed at making the system easier and more intuitive for users, so please try it.
There is a new training page on the larsoft.org website that provides useful information on training for LArSoft in one spot. While designed for people new to LArSoft, it has links to information that may be of value to all. It can be found at http://larsoft.org/training/
A valuable source of training are the annual LArSoft workshops. In 2017, the workshop will be held on June 20. The topics will be:
SPACK build system tutorial – In-depth, hands-on exploration of features, how to configure builds
Introduction to concurrency – What this means, why it is important, and what it implies for your code. A general discussion in advance of multi-threaded art release
Debugging and profiling tutorial
Continuous Integration (CI) improvements and new features
Information will be added to the Indico site including presentations.
While developing experiment-specific code, a developer may work on a feature (such as an algorithm, utility, improvement) that can be shared with the community of experiments that use LArSoft. In most cases, this can be done easily since the modified code does not affect the architecture and doesn’t break anything. But when the feature affects the architecture, a few more steps are needed to ensure that such contributed code can be properly shared across experiments and integrates well into the existing body of code. This article outlines the process to introduce and integrate into the core LArSoft code repositories both non-architectural features and architectural-affecting features.
The intent of the process is to achieve a smooth integration of new code, new ideas or improvements in a coordinated way, while at the same time minimizing any additional work required beyond the normal development cycle. Many changes will not require prior discussion. In cases with broad architectural implications getting feedback and guidance from the LArSoft Collaboration or the core LArSoft team early in the development cycle may be required.
Process for contributing a non-architectural, non-breaking change to LArSoft:
Develop the code including comments, tests and documentation.
Offer it by talking about it to LArSoft team members and maybe give a presentation at the LArSoft Coordination Meeting.
The rest of this article addresses a breaking, architectural change to LArSoft. Remember, all other cases will involve a more simplified process.
Process for contributing an architectural, breaking change to LArSoft:
Someone working on an experiment has an idea, an improvement, or a new feature that affects the LArSoft architecture that can be shared in the core LArSoft repositories.
Developer contacts the LArSoft Technical Lead or other members of the core LArSoft team to discuss the idea. Discussion can include an email thread, formal meeting, chat in the hallway, phone call, or any communication that works.
May find that the feature, or a suitable alternative, is already in LArSoft, thus saving the need to develop it again.
At this point, a decision will be made as to whether further discussion or review is needed, and where that discussion should take place. If other experts are likely to be required, a plan for including them in the process will be developed. The division of labor for the architectural changes will be discussed as well.
Developer prepares a straw proposal or prototype for the change.
For major changes as determined in step (2), the proposal should be presented at the biweekly LArSoft Coordination Meeting. Depending on the feedback, more than one presentation may be useful.
The developer writes the code, including comments, tests, and examples as needed, and keeps the LArSoft team informed on the status of work.
Any redmine pages or other technical documentation should be written during this time as well.
For new algorithms and services, an entry in the list of algorithmsshould be made.
When development is completed, request that it be merged onto the develop branch since this is a breaking change.
There is a cost in making things workable for other experiments, but the benefit is that other experiments develop software that is usable by all experiments. The more this happens, the more all experiments benefit.
When designing LArSoft code, it’s important to understand the core LArSoft suite and all the components used by it. It’s also important to follow the design principles and coding guidelines so that what is developed can be maintained going forward. A good place to start is at Important Concepts in LArSoft and by reading the material and watching the video about Configuration. It is important to follow the guidelines to have configuration-aware code that is maintainable with easy-to-understand configurations. The less time that is spent on debugging, the more time that can be spent on physics.
Once LArSoft contributors are aware of how LArSoft works, including the principles and guidelines for developing software, and have discussed the new feature with the LArSoft team, they will usually be asked to make a presentation at the LArSoft Coordination meeting. The idea here is to share the plan and the approach to solicit more ideas. Treat the initial presentation as a straw proposal–something that is designed to solicit feedback, not the final implementation that must be defended. At the same time, if a suggestion would double or triple the work required to implement it, and there isn’t a strong need for that suggestion to be implemented, it can be noted and set aside. The contributor is in charge of what he or she implements. The goal is to share software to reduce the development effort overall. It also encourages communication across experiments. The more collaborations can benefit from each other’s work, the better off we all are.
Details on developing software for LArSoft can be found at Developing with LArSoft wiki page. By contributing to the common LArSoft repositories, improvements to the code can then be used by everyone.
CERN had a one-day LArSoft tutorial designed for those who are joining reconstruction and analysis efforts in Liquid Argon experiments but are new to the LArSoft framework. These sessions were video recorded. The recordings are available along with the presentations – see the links at the end of this write-up.
Organizers of the event would like to acknowledge Marzio Nessi for supporting the event and Audrey Deidda and Harri Toivonen for their significant help with solving organizational issues.
LArSoft tutorial overview
Screen Shot from Video of the day
The participants came from many scientific research fields, not only from the Liquid Argon community, so in the morning session, the Liquid Argon TPC technology was presented. This introduction included discussion of a number of the challenges related to detection technology as well as challenges in data reconstruction and analysis. This background was followed with a short introduction to the LArSoft framework.
The morning hands-on session was led by Theodoros Giannakopoulos who did an introductory talk about the organization of the Neutrino Cluster at CERN. He also covered part of the LArSoft installation and explained how to set up the environment in Neutrino Cluster machines.
During the hands-on session, most of the participants logged into the Neutrino Cluster nodes using their own laptops with their own favorite operating system and shell. Having computing experts there was very important, especially Theodoros Giannakopoulos who was extremely helpful.
The purpose of the hands-on session was to learn how to run simulation and reconstruction jobs in LArSoft and how to visualize events to inspect results. As an example we chose 2 GeV/c test beam pion in the ProtoDUNE-SP geometry. Robert Sulej’s slides guided participants during the hands-on session. In many places, we pointed to the in-depth materials from the Fermilab LArSoft tutorial and also linked to slides from the YoungDUNE tutorial, e.g. event display slides were very helpful.
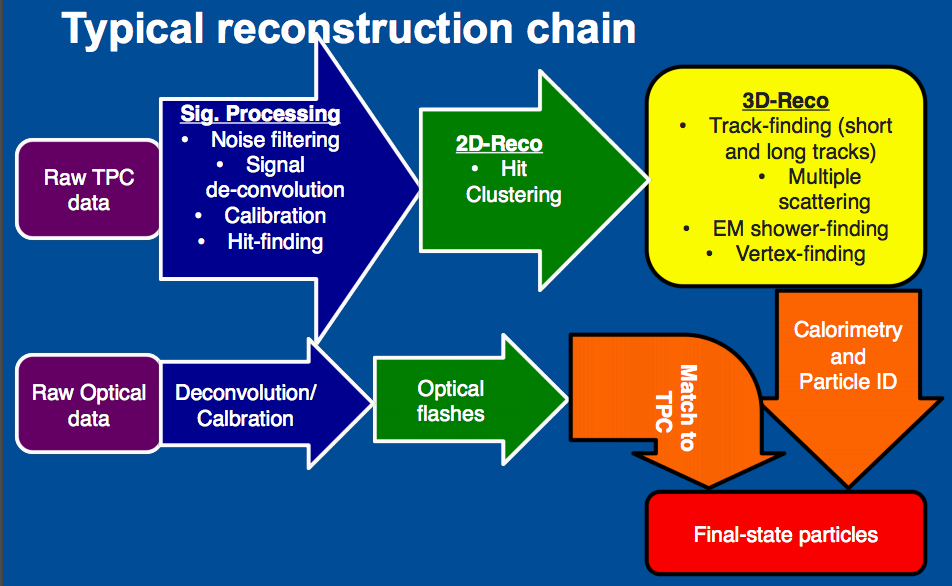
The afternoon session started with a talk by Wesley Ketchum titled “Reconstruction as analysis.” The reconstruction in Liquid Argon is a challenging task, but developing reconstruction algorithms to overcome a problem is also a great source of satisfaction. It is also very important to make progress in the Liquid Argon data analysis. As Wes said, it is the “process of taking raw data to physically-meaningful quantities that can be used in a physics analysis.” Wes presented an overview of reconstruction algorithms in LArSoft and several use cases from MicroBooNE data analysis experience.
Diagram from Wesley Ketchum’s presentation
Wes prepared examples for the afternoon hands-on session during which he introduced Gallery as a light-weight tool for simulation and reconstruction results analysis appropriate also for the exploratory work before code is moved to the LArSoft framework. A short introduction was followed by coding examples. The last part of the hands-on session explained how to “write and run your own module, step by step.”
Participants learned about the organization of LArSoft modules and algorithms and their configuration files. The aim of the coding exercise was to access information stored in data products (clusters) and associations between them (hits assigned to clusters) so participants could make histograms of simple variables such as number of cluster. They also had the opportunity to learn about matching the reconstruction results to the simulation truth information.
Two weeks after the tutorial, several people are still in contact with us, progressing with their understanding of the framework and starting their real developments. The tutorial reached many members of double phase LArTPC technology. This shows the advantages of having a detector agnostic approach where development efforts can be efficiently used. In the end we are all heading towards the same physics goals.
Links to Material
The video from the morning session is available here. It covers the following presentations:
Tutorial part I – Dorota Stefan (CERN/NCBJ (Warsaw PL)) , Wesley Ketchum (Fermi National Accelerator Laboratory) , Robert Sulej (FNAL / NCBJ)
Note, you need a CERN user account to access cluster and do exercises using preinstalled software. It is possible to use local installation on a laptop. See the information at the beginning of the Indico page about the session.
The video from the afternoon session is available here. It covers the following presentations: