This summer, I helped create the first Liquid Argon Software (LArSoft) shared algorithm repository. Shared repositories are git-maintained directories of code that do not require the underlying framework or other LArSoft dependencies. By using shared repositories, development of common software can occur both in LArSoft and in a third-party system. One such system is LArLite, a lightweight analysis framework developed by MicroBooNE scientist Kazuhiro Terao. Users of LArLite only need to set up the desired shared repositories to gain access to the code.
I worked on LArSoft/LArLite integration within the Scientific Computing Division (SCD), which provides core services to the multitude of experiments being conducted at Fermilab. By enlisting computer scientists as a separate but well-connected group to the experiments, expert knowledge is focused to provide experiment analysts with an abundance of purpose built, robust computing tools. I used the groundwork laid by a SCD project finished in the spring of 2016 to support shared repositories in LArSoft.
The computing needs of each experiment are unique, though all share some common elements. For example, many experiments at Fermilab employ art as their event processing framework, producing well-documented and reproducible simulations. Since its creation, the development of LArSoft has been guided by the needs of experiments to provide a sturdy framework for simulation, reconstruction and analysis of particle physics interactions in liquid argon. LArSoft is a collection of algorithms and code that exist in many git repositories, and corresponding products managed by the Unix Product Support (UPS) system. The UPS system provides a simple and safe method of establishing working environments on Unix machines while avoiding dependency conflicts. This system is available on most computing systems provided by Fermilab and can also be easily set up by users on their own systems. UPS is relied upon for ensuring consistency between software environments. To cater to users’ needs, LArSoft has to be flexible to incorporate useful code developed independently of Fermilab supported machines.
The LArLite code repository was written to allow for liquid argon analysis in a lightweight, python friendly system with a fast setup procedure. Development and progress on algorithms has been made in this framework particularly because of its quick setup time on personal computers that don’t have a well populated UPS area. Many of the core algorithms used in LArLite, however, are either not available in LArSoft or follow a very similar design to those in LArSoft causing a duplication of effort.
Having two copies of an algorithm exist in different build environments is undesirable as this creates discrepancies and incompatibilities. These discrepancies and incompatibilities become increasingly hard to rectify if changes are made on either side. For this reason, the shared repository must be able to be built with both native build systems. Another issue arises as LArLite was not developed with shared repositories in mind and has no tagged releases. LArLite only has a monitored master branch which may not be compatible with shared repositories in the future. For shared LArLite code to be reliably used within LArLite as well as LArSoft, a stable supported release needed to be created.
Working in the SCD, I created a first demonstration of using shared repositories for merging LArSoft and LArLite by moving the LArLite code GeoAlgo into the shareable repository larcorealg. Building on the earlier groundwork, I ensured compatibility between the two native build systems, CetMake and GNUmake, and resolved dependency issues by using the UPS system and editing LArLite core files. After this demonstration, a more complicated LArLite algorithm, Flash Matching, was moved to a shared repository in coordination with the algorithm developer, Ariana Hackenburg. Here, LArLite services and data products were interchanged for their corresponding and newly shared versions in LArSoft. An integrated LArSoft/LArLite system benefits all users, as it maintains the setup speed of LArLite to support a rapid development cycle, while allowing experiments like MicroBooNE to officially adopt and implement important algorithms as part of LArSoft with no additional effort. Most importantly, it allows users on both sides to access previously inaccessible algorithms and data.
The introduction of LArLite algorithms into shared git repositories demonstrates the potential for including other third-party software in a similar fashion. Collaborative liquid argon software in shared repositories will require the work and commitment of many physicists. It’s my hope that the effort is made to include more algorithms into shared repositories since it has the potential to improve liquid argon based experiments at Fermilab.
The 2016 LArSoft Usability Workshop on June 22 and June 23 focused on usability, interfaces and code analysis. Over 50 people registered, filling the rooms. Remote attendance was supported as well. The section titles listed below are links to the material presented, where available.
During the meeting, a dozen issues were recorded at: https://cdcvs.fnal.gov/redmine/projects/larsoft/issues
About half of the sessions were recorded. (Not by design. This was the first time we tried to capture video.) Note that these video recordings were not the main point of the workshop, and they have been edited to avoid side conversations at the beginnings and ends of presentations and beeps as people joined the bridge. Feedback is appreciated. Please contact klato@fnal.gov.
The two-day workshop began with a review of usability and the conference by Erica Snider. LArSoft is the users’ code. The Fermilab LArSoft team is here to help and input from the users is critical to what we do. Interruptions were encouraged throughout the workshop.
Panagiotis Spentzouris – Welcome
Although Panagiotis Spentzouris was not able to attend the opening session, during his remarks on the second day, he said, “LArSoft is one of the centerpieces of our strategy for developing and supporting common tools for experiments with experiments.” It’s not an easy model. It requires discipline from the users and SCD support. The work of the experts on the SCD side and the users’ work has made it a success, and it is important to continue along this path.
Steve Brice – Steering Group Welcome
Steve Brice gave the steering group welcome. (You can listen to part of it below, if you like.)
The liquid argon effort involves many detectors in increasingly complex ways with experiments being able to learn from one another. The LArSoft team has achieved enormous success in connecting the different endeavors. Going forward, it will get more difficult. “Keep up the good work. It’s greatly appreciated and widely acknowledged.”
Usability is defined by ISO 9241-11 as, “The extent to which a product can be used by specified users to achieve specified goals with effectiveness, efficiency and satisfaction in a specified context of use.”
After last year’s workshop, LArSoft interviewed a number of users and stakeholders, identified several areas of intervention and collected a list of desirable items. We selected some of them: examples and use of associations. There is a wiki page listing the new examples, and we’re happy to write more. The examples follow best practices including documentation in Doxygen format. The LArSoft team endorses test writing and can provide help in writing tests. Several questions/comments covered issues about recording tests, how tests evolve, the need for user help to make them better as well as making the code better by extending the interface. The video of the presentation is available here.
We have to balance the ability to introduce new ideas and new features quickly with writing production-quality code. Users depend on production quality and developers depend on agility. Both of these are important to usability. Discussing code changes at a coordination meeting is necessary for all changes that affect behavior, i.e. most cases.
There are policies, guidelines and standards at all levels: design principles, coding guidelines, git branching model and documentation guidelines. The point of this model is to produce shareable, relatively uniform code that is recent. That’s why we have weekly releases. The focus is on finding consensus across experiments for changes, which requires gate-keeping. We want to find the right balance- enough agility to keep people interested in producing code with enough gate-keeping to keep people using it. Are we in the right spot? The video of the presentation is available here.
The Pandora multi-algorithm approach to pattern recognition uses large numbers of algorithms (80+), each designed to address specific topologies and gradually build-up a picture of events. It relies on functionality provided by the Pandora Software Development Kit (SDK), documented in EPJC 75:439. Algorithms are structured around a number of key operations and can be written in pseudo-code form; what differs between real algorithms is the precise logic, based on topological information, that determines when to request operations such as merging or splitting Clusters (collections of Hits). Ideas about Event Data Model requirements, developer training, communication and style guides were presented, alongside feedback from Pandora developers. The best features include the ability to quickly test new ideas, that the SDK services can be trusted completely, the simple XML-based configuration and the visual debugging functionality (seeing a problem presented visually can lead to rapid understanding). Things that haven’t worked so well include the build mechanics (a difficulty associated with inclusion in multiple software frameworks) and attempts to provide some globally reusable features (the current geometry model, and some Hit properties, still lean towards their collider-detector usage). The video of the presentation is available here.
Good documentation is needed at all levels. For example, when documenting a LArSoft algorithm, it’s important to have a high-level view available at http://larsoft.org/list, which includes a link to a detailed document, like a technical note available to the entire LArSoft community. Comments in the header and in the implementation code should be in a format that enables Doxygen to interpret them. It’s also important to describe important parts in the code. See LArSoft wiki (Redmine) page Code Documentation guidelines for a suggested template to follow. Don’t forget in-line comments in the code for maintainability. The video of the presentation is available here.
We are looking at new build systems because the current system using environment variables has problems running on new operating systems and in Linux containers. Spack-builds a stack of dependent software packages. It is open source, well documented and community supported with information available from:
Spack generates environment modules that can be used to set up the environment. It will have a different hash. There are still things that need to be worked out. The video of the presentation is available here.
Kyle walked through setting up a FHiCL file, including how to set up a PROLOG, the #include facility and the rules about using it. The directory of a file to be included must be present on the FHICL_FILE_PATH environment variable. Don’t abuse #include. Only #include files that contain only prologs. A common frustration is how to know what parameters to specify for a given module. While looking at the source code is one solution, it would be better to devise a system that documents itself. Kyle demonstrated the ‘art –help’ and ‘art –print-available-modules’ facilities. For the ‘art –print-description’ facility, the allowed configuration is printed to the screen if users provide the appropriate C++ structure. The main point is that easy-to-maintain and understandable code means more time spent on physics instead of debugging coding errors.
When designing its use of FHiCL, Mu2e set two goals: parameters should have a single point of maintenance and FHiCL that can be run interactively should be runnable on the grid without editing. Rob’s talk showed several FHiCL fragments from actual Mu2e MC production FHiCL files. One technique is to define base configuration fragments and apply deltas to that base; this naturally leads to deep configuration hierarchies. The trick to making an interactive FHiCL file grid-ready is to design the grid scripts and the interactive FHiCL files together – the grid scripts do their job by applying prefixes and postfixes to the interactive FHiCL file. We have never needed to “reach in and edit” a FHiCL file as part of a grid job.
gallery provides access to event data in art/Root files outside the art event processing framework executable without the use of EDProducers, EDAnalyzers, etc., thus, without the facilities of the framework (e.g. callbacks from framework transitions, writing of art/ROOT files). The distribution bundle larsoftobj was introduced to give a single-command installation for all the UPS products needed to use gallery to read LArSoft-created art/ROOT files. Installation instructions are at http://scisoft.fnal.gov/scisoft/bundles/larsoftobj/ (look for the newest version and view the HTML file for instructions). Marc provided a demo that read through 100 files and filled three histograms. He showed the code and talked through it, answering questions.
‘Discussion of Ideas’ and ‘Using tips and techniques on your code.’
Several issues were recorded from the afternoon working sections.
This is about things we should have been doing all along. The HEP Analysis Peer Review Process works really well and is similar. Rob covered what we do well with HEP and Integration Testing and some lessons learned from the Mu2e Reviews such as a lot of the value came from the prep work for the review. Lessons from the software development community are that many errors were found by the author when preparing for the review. Use the specialists. Since much value is in the preparations, that means having deadlines, profiling and prep presentation.
Writing good code is a process. Things would get better if we reviewed our code. Want the code analysis process to be as light-weight as possible for the situation and to be performed collaboratively with the code author(s). Erica went through the five basic steps of a review and the recent example of PMA analysis. LArSoft hopes to create a culture that seeks code analysis. Thanks to Mike Wallbank and Bruce Baller for volunteering their code for the afternoon code analysis during the workshop.
If you’re going to generate events with GENIE, read https://cdcvs.fnal.gov/redmine/projects/nutools/wiki/GENIEHelper. “It will save you a world of hurt.” The improvement in usability and performance of the interface to Geant4 needs to be a cooperative effort between the PDS group and LArSoft. The video of the presentation is available here.
Types of profiling include timing and memory. The tool igprof can do both. Chris covered how to use igprof. The video of the presentation is available here.
Code and performance analysis working groups
Two groups focused on analyzing two coding examples volunteered by their authors, Bruce Baller: TrajCluster algorithm and Michael Wallbank: BlurredCluster algorithm.
Feedback
Comments include:
I enjoyed talking about LArSoft and the future of the project. I was very encouraged by all that was said and feel exciting times lie ahead for the software! Also enjoyed the code analysis and discussion of new feature of art/fhicl.
The LArSoft steering group welcome set a strong, positive tone for the workshop.
It was better than expected. I supposed it was something more introductory but actually it was oriented to people who wants to contribute to LArSoft and not only be users. So it is very helpful for my work.
It was a little more advanced/high-level than I’d anticipated, but very useful.
It did not have as many overview talks as I expected. And there seemed to be few talks by the experiments.
Useful how-to instructions on slides. In the code review section, Mike Wallbank was cutting and pasting igprof commands from Chris Jones’s highly useful slides.
I was able to discuss with the experts about the issues I didn’t understand or what I thought it was missing.
by Jack Weston for the Pandora Team, Cavendish Laboratory, University of Cambridge
The Pandora multi-algorithm approach to automated pattern recognition affords a powerful framework for event reconstruction in fine-granularity detectors, such as LAr TPCs.
With its origins at the proposed International Linear Collider (ILC) experiment, the Pandora project began in 2007 as a particle flow calorimetry algorithm; that is, an algorithm that reconstructs the paths of individual particles, taking advantage of high-granularity tracking detectors and calorimeters. Since then, Pandora has grown into a flexible software framework for solving generic pattern recognition problems that involve points in time and space, particularly suited to the “photographic quality” images produced by LAr TPCs.
Behind Pandora’s approach to pattern recognition is the multi-algorithm paradigm: the idea that each particular topology can be addressed by one or more relatively straightforward, self-contained algorithms. Under this paradigm, solving a complex pattern recognition problem, such as reconstructing particles in a LAr TPC (Figure 1), requires a sizable chain of such algorithms, whose order of execution is able to exhibit data-dependent nonlinearity and recursion. Some algorithms are very sophisticated, other rather simple; together, they gradually build up a picture of the events. This approach marks a significant departure from the traditional practice of single algorithms for shower finding and track fitting, for example, and promises to provide a robust way of tackling intricate pattern recognition problems. It also affords a rich development environment since many algorithms, each addressing a given topology in a different way, can be safely bound together and work in harmony. This approach is able to provide a more sophisticated and accurate reconstruction than would be reasonably achievable by writing one algorithm alone.
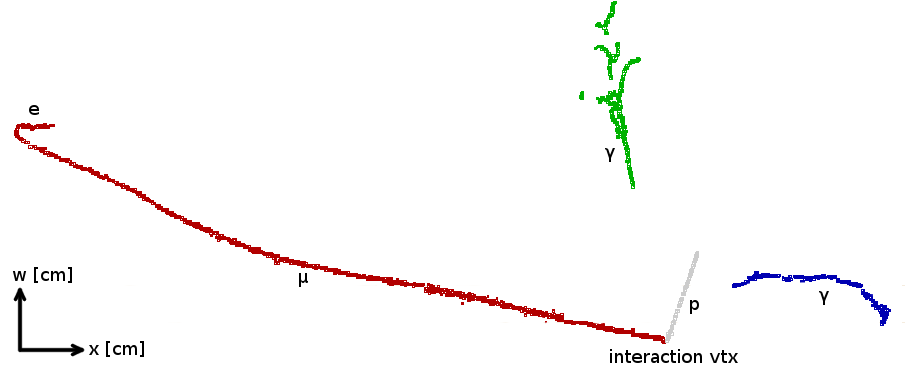
Figure 1: A 3D Pandora reconstruction, projected into the w-view. The input hits are from a Monte Carlo simulation of a 0.8 GeV charged-current νμ event with resonant π0production. The event shows a proton (grey), a muon (red), and two photons (green, blue). The event is visualised using the Pandora event display, where the x axis represents a distance derived from drift time and the w axis a distance derived from the number of the wire recording the ionisation signal.
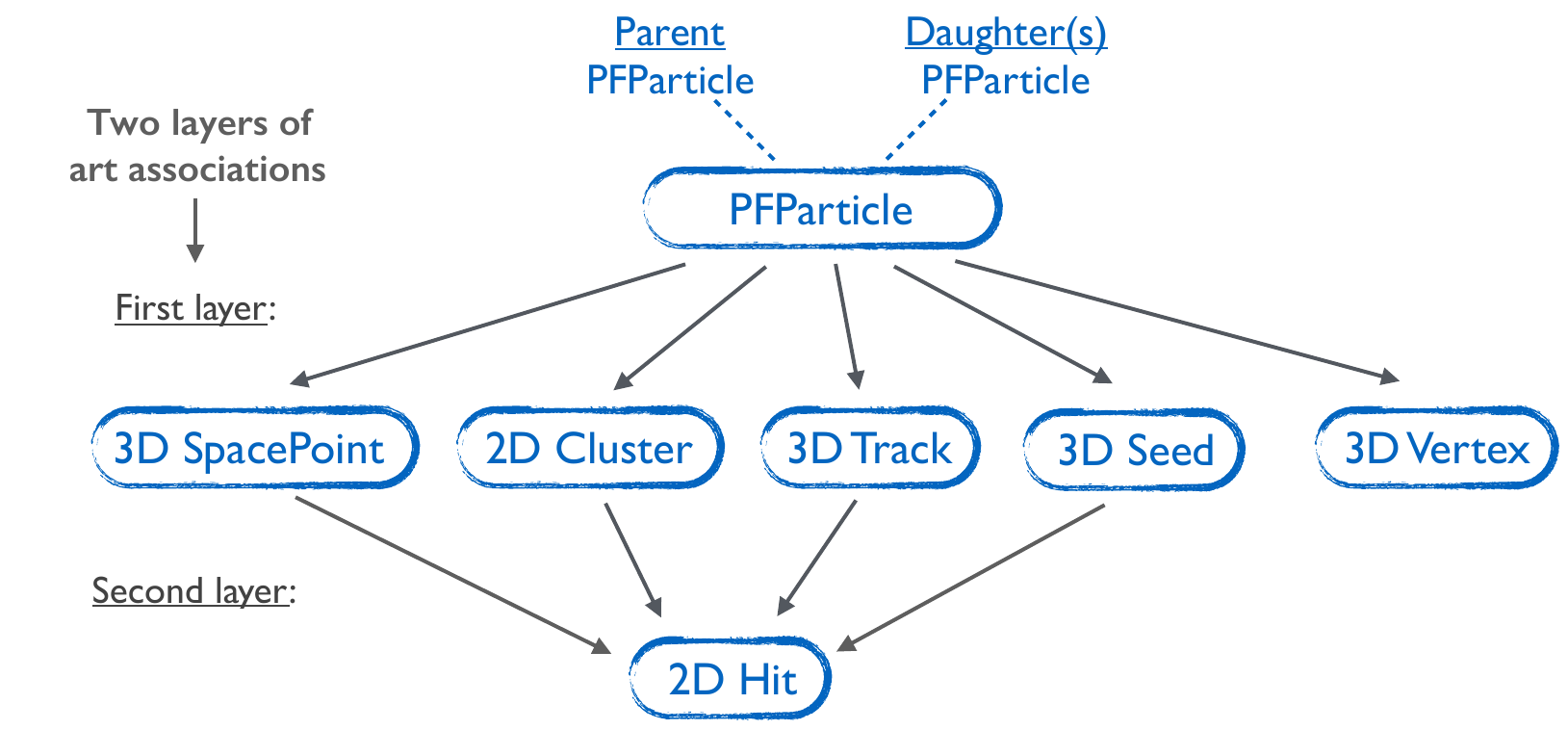
Figure 2: The Pandora reconstruction output in the LArSoft Event Data Model (EDM). The PFParticle object is associated with the 3D hits, clusters, tracks, seeds and vertices of the particle it represents. In addition, PFParticle parent-daughter links allow representation of a full particle hierarchy.
In a LAr TPC, the readout provides three 2D images of the event within the active detector volume. Each image shares a common coordinate, derived from the drift time. The second coordinate is derived from the number of the wire recording the ionisation signal in a given plane. The reconstruction begins with cautious, track-oriented 2D clustering before using a series of topological-association algorithms that conservatively merge and split the 2D proto-clusters. Considering pairs of 2D clusters, an extensive list of possible 3D vertex positions is produced. A score is calculated for each candidate vertex and the best one is chosen. The 3D vertex position can then be projected back into the readout planes and used, for example, to split the 2D clusters at the projected vertex position if required. To reconstruct 3D tracks, Pandora uses track-matching algorithms to exploit the time-coordinate-overlap between all possible groupings of 2D candidate clusters in different planes to predict the position of the cluster in the third plane. The time-overlap span, the proportion of matching sampling points and a chi-squared value are all neatly stored in a rank-three tensor, where the three indices are the clusters in each of the three views. The tensor is interrogated by a series of algorithm tools which identify any matching ambiguities and make careful changes to the 2D clusters until the tensor is diagonal and the cluster combinations are unambiguous. These matches are stored in ‘particles’, which provide a convenient means for collecting together objects reconstructed in the three readout planes.
Showers can then be reconstructed (in 2D) by attempting to add branches to long clusters that represent shower spines—the showers are grown outwards from a spine by identifying branches, then branches-of-branches, and so on. To synthesize the 2D shower information into 3D showers, the tensor ideas can be re-used: the fitted shower envelopes for each pair of views are used to predict an envelope in the third view, and the enclosed hit fraction in this view is stored in a tensor, along with other cluster-matching properties. An analogous process of tensor-diagonalisation then yields the best 3D matches. Finally, 3D hits are created and the track, shower and vertex information is brought together to produce a full particle hierarchy, where each daughter particle comprises metadata, a list of 2D clusters, a 3D cluster, a 3D interaction vertex, and a list of any further daughter particles (Figure 2).
Figure 3: Pseudocode demonstrating procedures for creating and merging clusters and their associated API calls. This logic is almost identical between algorithms, regardless of the pattern recognition problem.
Such a multi-algorithm approach poses a significant software challenge. The Pandora Software Development Kit provides a software environment designed specifically for this purpose: it offers the basic building-blocks for abstracting high-level structure from a collection of points, such as clusters, as well as the means for users to adapt these building-blocks to suit their problem. It also provides the framework for running the complex, nonlinear chain of algorithms required and automates the handling of the building-blocks, allowing developers’ algorithms to focus on physics rather than technicalities like memory management. This facilitates rapid algorithm development. Instances of the objects in the Event Data Model (EDM) are owned by Pandora Managers, which are responsible for object and named list lifetimes. These Managers automate a complete set of low-level operations that facilitate the high-level operations required by pattern recognition algorithms. The algorithms contain the step-by-step instructions for finding patterns in the input data and use APIs to modify, create or destroy objects and lists. Much of the technical difficulty in writing highly object-oriented algorithms like these is alleviated by Pandora’s provision of APIs able to access and manipulate objects in the Pandora EDM, such as getting a named list of hits or creating new clusters. These APIs can be used in algorithms to interact with Managers and provide common low-level logic in a concise way. Examples of the API calls that would be encountered in algorithms for creating and merging clusters are shown in Figure 3. Such procedures are common to all pattern recognition problems, differing only in the logic that determines the ‘best’ clusters, which is specific to the problem at hand. Pandora also contains a ROOT-based event display that allows the navigation of particle hierarchies, 2D and 3D hits, clusters and vertices, as well as providing invaluable visual debugging possibilities within algorithms.
Pandora works in conjunction with LArSoft by providing the ideal framework for the pattern recognition step. An art producer module creates Pandora instances, and configures and registers algorithms. For each event, hit information is passed from LArSoft into Pandora and, at the end, the Pandora reconstruction output, in the form of PFParticles, is passed back to LArSoft. Whilst LArSoft remains the core framework for the simulation and reconstruction process, this multi-algorithm reconstruction cannot be easily realised using LArSoft alone: Pandora provides the tools necessary for the job, as well as an environment conducive to developing algorithms under this paradigm. All interaction between LArSoft and Pandora is handled by the LArSoft module LArPandora, which serves as their mutual interface as well as translating Pandora’s inputs and outputs into the required formats (Figure 4). This module depends only on the library LArPandoraContent which, in turn, depends only on the Pandora SDK and visualisation libraries.
Figure 4: Diagram indicating the structure of the Pandora packages in LArSoft. This includes the LArSoft module LArPandora, the LArPandoraContent library and the SDK and monitoring libraries. Note that monitoring library has a ROOT dependency. The SDK and monitoring library provide a framework that is independent of the pattern recognition problem to be solved: all the LAr TPC reconstruction logic resides in the LArPandoraContent library. The LArPandora module provides a LArSoft/Pandora interface for translating Pandora’s inputs and outputs.
At MicroBooNE, two different algorithm chains are used: PandoraCosmic, optimised for the reconstruction of cosmic rays and their daughter delta rays, and PandoraNu, optimised for the reconstruction of neutrino events. By running the PandoraCosmic chain first, cosmic rays can be identified and removed, providing the input for the PandoraNu reconstruction. Starting by manipulating the three sets of hits in 2D before synthesising these into 3D structures, Pandora gradually builds up a picture of the event through clustering, vertexing, and track and shower reconstruction. The full reconstruction currently consists of nearly 80+ different algorithms that, together, abstract from the input 2D hits an information-rich 3D particle hierarchy, including information like particle types, vertices and directions.
At the upcoming DUNE experiment, the detector will comprise multiple LAr TPC detector volumes, each of which will provide two or three 2D images. Events may cross the boundaries between volumes, posing a new challenge for the reconstruction. To solve this problem, a Pandora instance is created for each volume, which provides a MicroBooNE-like reconstruction of that detector region. Bringing together these independent reconstructions, logic is then required to decide which particles to stitch together across gaps—and to determine which particle is the ‘parent’. While algorithm re-optimisation to suit the different beam spectrum is required, the reusable Pandora interfaces ensure that MicroBooNE developments are directly applicable to DUNE.
Pandora provides a flexible development platform for developing, visualising and testing pattern recognition algorithms. The LArPandoraContent library offers an advanced and continually improving reconstruction of cosmic ray and neutrino-induced events in LAr TPCs and is used by the MicroBooNE and DUNE experiments. Pandora’s GitHub page can be found at https://github.com/PandoraPFA, with an accompanying paper describing the SDK on arXiv: http://arxiv.org/pdf/1506.05348v2.pdf (EPJC 75:439).
The goal of this material is to help new LArSoft users understand the big picture of what is going on within the code. The aim is not to show specific code examples but to lay the foundation for the conceptual understanding of the basic steps in simulation, geometry, reconstruction, algorithms, services and designing, coding and testing LArSoft. The main page can be found here.
We’ve started documenting the algorithms in LArSoft, and need your help. If you have an algorithm name and an email, you can get started. See this page for more information. As an example of an algorithm added, Bruce Baller added the information for ClusterCrawlerAlg. It can be seen here with a link to more detailed information.
There is a forum outside of Fermilab, hosted by the University of Manchester, to discuss LArTPC software. This forum, called www.larforum.org, has been in existence for several years. Andrzej Szelc administers the site with the help of several moderators. These moderators are experienced users of LArSoft and are part of the LArSoft Collaboration. Please consider adding your suggestions to the various topics such as:
LArSoft 101 – for people new to LArSoft to ask questions
Redmine is a web-based software project management application which includes a documentation wiki. Erica Snider and Katherine Lato continue to update the LArSoft Redmine pages, starting from the main page and going through all lower-level items. Ones of interest include:
There will be regular notes about issues of interest to LArSoft developers and users. Please contact klato@fnal.gov if you have suggestions about what to include or if you have feedback.
INSPIRE is a High-Energy Physics (HEP) literature database. It is possible to have private views. See this page for information about how to login to see LArSoft documents. There is not a login link on the main page, because it would be misleading for most INSPIRE users. None of the notes collections of any experiment is accessible via the main landing page of INSPIRE. So you have to login to see the ‘LArSoft Notes’ document, but that means they aren’t publicly available even though they’re in INSPIRE.
Katherine and Erica have been going through the Redmine web pages, revising the information and replacing links to old information. A useful page to look at is the Quick Links page which includes links to experiment specific Quick Start Guides.
 This summer, I helped create the first Liquid Argon Software (LArSoft) shared algorithm repository. Shared repositories are git-maintained directories of code that do not require the underlying framework or other LArSoft dependencies. By using shared repositories, development of common software can occur both in LArSoft and in a third-party system. One such system is LArLite, a lightweight analysis framework developed by MicroBooNE scientist Kazuhiro Terao. Users of LArLite only need to set up the desired shared repositories to gain access to the code.
This summer, I helped create the first Liquid Argon Software (LArSoft) shared algorithm repository. Shared repositories are git-maintained directories of code that do not require the underlying framework or other LArSoft dependencies. By using shared repositories, development of common software can occur both in LArSoft and in a third-party system. One such system is LArLite, a lightweight analysis framework developed by MicroBooNE scientist Kazuhiro Terao. Users of LArLite only need to set up the desired shared repositories to gain access to the code.